基本的にREGEXEXTRACT関数を使っていますが、「特定の文字のうちn番目のもの以降(より後)を抽出する例」は難解なのでMID/FIND関数を使う例も併せて紹介します。
最初のもの以降を抽出する
「特定の文字のうち最初のもの」以降の部分を抽出する例です。
次の画像ではB3:B7セルに対象となるテキストが記録されています。C3セルにREGEXEXTRACT関数を使った式を入力してC7までフィルコピーすることで、最初の「☆」以降の部分を抽出しています。
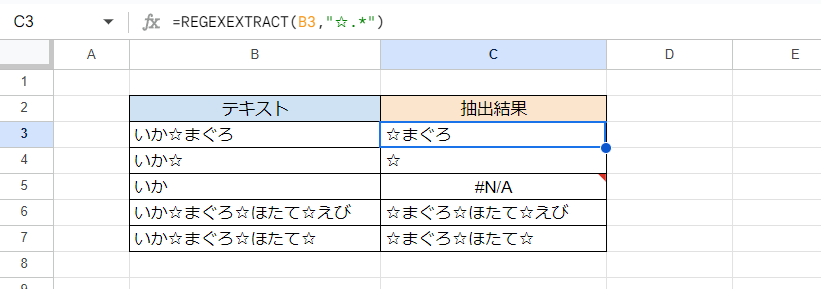
C3セル(下方にフィルコピー)
=REGEXEXTRACT(B3,"☆.*")
REGEXEXTRACT関数はテキストのうち指定した正規表現(第2引数)にマッチする部分を抽出する関数です。
第2引数のうち「.*」というのは「0文字以上の文字」を意味しています。つまり「☆.*」というのは「☆とその後に続く0文字以上の文字」という意味になります。結果的に最初の「☆」とそれ以降の文字列が抽出され、最初の「☆」の後に何もない場合は「☆」だけが抽出されます。
なお、Googleスプレッドシートで使える正規表現の基本的な内容やREGEXEXTRACT関数については次の記事で取り上げていますので参考まで。
(Gスプレッドシート)正規表現の基本的な使い方まとめ - いきなり答える備忘録
(Gスプレッドシート)REGEXEXTRACT関数の使い方 - いきなり答える備忘録
最初のものより後を抽出する
こちらは「特定の文字のうち最初のもの」より後の部分を抽出する例です。

C3セル(下方にフィルコピー)
=REGEXEXTRACT(B3,"☆(.+)")
「.+」の部分は「1文字以上の文字」という意味です。また、カッコを使うことでその部分だけを抽出できます(カッコの外側は検索の対象にはなるが抽出はされない)。
つまり「☆(.+)」は「☆の後に続く1文字以上の文字」という意味になりますので、結果的に最初の「☆」より後の文字列が抽出されます。最初の「☆」の後に何もない場合はなにも抽出されずエラーとなります。
n番目のもの以降を抽出する
次の画像では、テキスト中の2番目の「☆」以降の部分を抽出しています。

C3セル(下方にフィルコピー)
="☆"®EXEXTRACT(B3,"(?:[^☆]*☆){2}(.*)")
一気に難解になりますが、「[^☆]*」は「☆以外からなる0文字以上の文字」を意味します。よって「[^☆]*☆」は「☆以外の0文字以上の文字と、それに続く☆」という意味です。
また、「{2}」はその前にあるカッコ内の正規表現を2回繰り返すことを意味します。よって「(?:[^☆]*☆){2}」は「2つ目の☆まで」という意味になります。カッコの中に「?:」という部分がありますが、これによりカッコを使いつつも抽出対象から除くことができます。
以上より「(?:[^☆]*☆){2}(.*)」というのは「2つ目の☆の後にある0文字以上の文字」ということになります。ただしそれだと「☆」は抽出できないので先頭の「"☆"&」で補っています。
備考ですが最後のカッコはいらないように見えるものの必須で、外すと異なる結果になります。
なお、上記の式中の「{2}」を「{3}」に変えると次のようになります。3つの「☆」がなければエラーになり、ちょうど3番目の「☆」でテキストが終わる場合はエラーにならず「☆」が抽出されているのがわかります(REGEXEXTRACT関数が0文字の文字列を抽出するから)。

さて、いろいろ書きましたが上記の内容はかなり難しいので、伝統的なMID/FIND関数を使って2番目の「☆」以降を抽出する例を記しておきます。
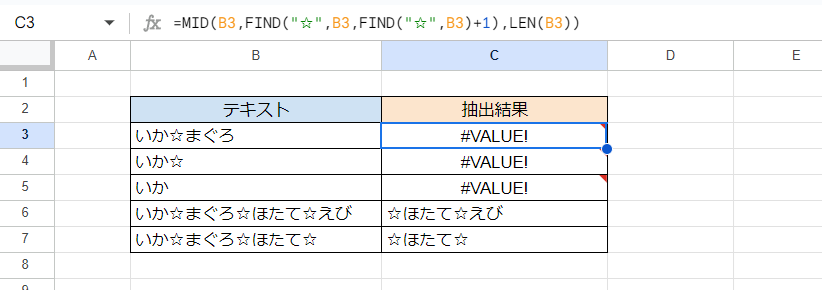
C3セル(下方にフィルコピー)
=MID(B3,FIND("☆",B3,FIND("☆",B3)+1),LEN(B3)) MID関数の第2引数(抽出開始位置)を「FIND("☆",B3,FIND("☆",B3)+1)」としています。これは「テキスト中の最初の☆の位置の次から検索を開始して最初に見つかる☆の位置(テキストの最初から数えて何文字目か)」という意味です。あとはMID関数でその位置以降の部分を抽出しています。第3引数(抽出文字数)の「LEN(B3)」は「テキストの文字数」を表すので数字としては大きすぎるのですが、これでエラーにならずテキストの最後まで抽出できます。
これはこれで難しいですし、同様に3番目や4番目以降を抽出しようとするとさらにFIND関数をネスト(入れ子)することとなりドンドン長くなるのが欠点です。
n番目のものより後を抽出する
次の画像では、テキスト中の2番目の「☆」より後の部分を抽出しています。

C3セル(下方にフィルコピー)
=REGEXEXTRACT(B3,"(?:[^☆]*☆){2}(.+)") ほぼ1つ上の例と同じですが最後のカッコ内が「.+」つまり「1文字以上の文字」となっています。
画像は省略しますが、テキストが2番目の「☆」で終わる場合はエラーが返ります。
次の画像ではMID/FIND関数を使って、2番目の「☆」よりも後の部分を抽出しています。

C3セル(下方にフィルコピー)
=MID(B3,FIND("☆",B3,FIND("☆",B3)+1)+1,LEN(B3)) これも1つ上の例(n番目のもの以降を抽出)とほぼ同じですが「+1」が1か所増えており、これで2番目の「☆」の次の文字以降が抽出されます。
3番目以降を抽出する場合はネストに頼ることとなり式が長くなるのも1つ上の例と同様です。
最後のもの以降を抽出する
次の画像ではテキスト中の最後の「☆」以降の部分を抽出しています。

C3セル(下方にフィルコピー)
=REGEXEXTRACT(B3,"☆[^☆]*$")
上記の「n番目~」の例と比べるとかなり簡単です。
まず「$」というのはテキストの末尾を意味します。よって「☆[^☆]*$」は「☆、☆以外の0文字以上の文字、テキストの末尾、が連なったもの」、つまりは「最後の☆以降の部分」という意味になります。
最後のものより後を抽出する
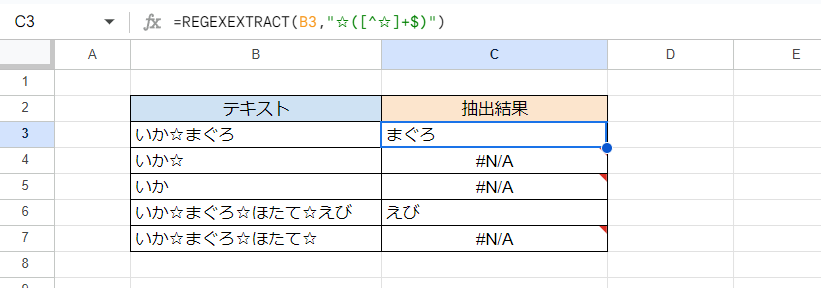
C3セル(下方にフィルコピー)
=REGEXEXTRACT(B3,"☆([^☆]+$)")
ほぼ1つ上の例と同じですがカッコを使うことで「☆」を抽出の対象から除き、「*」を「+」に代えることにより最後の「☆」のあとに1文字以上存在しなければ抽出しないこととしています。結果として最後の「☆」は抽出されず、その後に何もない場合はエラーとなります。