- REGEXEXTRACT関数は、指定した正規表現にマッチする部分を抽出します。基本的に複数の部分がマッチする場合は最初のものだけを抽出します。
- グループ化(カッコ)の効果に特徴があります。
手順
基本的な抽出

B2:B4には抽出の対象となる文字列が記録されています。
これに対してC3セルに次のような式を入力し、さらに下方にコピーして、各セルの文字列の一部を抽出しています(以下同様)。
この例では、文字列中の最初の3文字を抽出しています。
C3セル
=REGEXEXTRACT(B3,"...")
正規表現の「.」は任意の1文字にマッチします。つまりどのような文字にもマッチするので、「...」と指定することで文字列中の最初の3文字を抽出することができます。
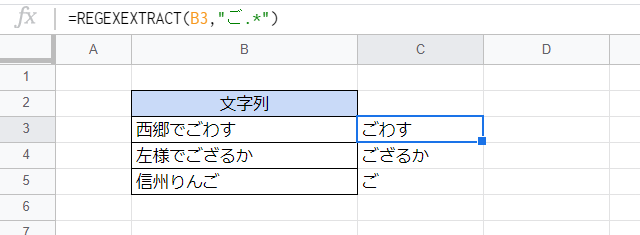
量指定子「*」の使用例です。「*」は直前の文字の0回以上の繰り返しにマッチします。
ここでは次のような式により、文字列中の「ご」の字以降の部分を抽出しています。
C3セル
=REGEXEXTRACT(B3,"ご.*")
「.*」は任意の文字列にマッチします。いくら長くてもその分だけマッチしますし、逆に0文字であっても構いません。よって「ご.*」は「ご」の文字以降の部分にマッチしますし、ただの「ご」にもマッチします。
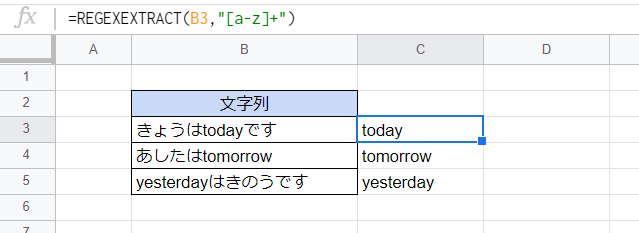
こちらは量指定子「+」と、一定の文字範囲を表す「[○-○]」の併用例です。
ここでは文字列中の半角英小文字を抽出しています。
C3セル
=REGEXEXTRACT(B3,"[a-z]+")
「[a-z]+」は1文字以上の半角英小文字にマッチします。このように複数の文字種を一括して指定できるのが正規表現の強みで、LEFT,MID,RIGHTやFIND,SEARCHなどを用いる旧来の文字列抽出よりもはるかに強力な抽出が可能となっています。
なお、正規表現では基本的に大文字と小文字を区別しますので注意が必要です。「=REGEXEXTRACT(B3,"[A-Za-z]+")」などとすれば、半角英大文字と半角英小文字が混じっていても抽出できます。
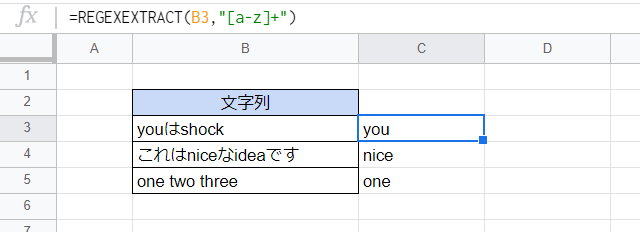
ところで、REGEXEXTRACT関数は正規表現にマッチする部分のうち最初のものしか抽出しません。
ここでは1つ上の例と同じ式を入力していますが(各文字列中に2か所もしくは3か所ある)1文字以上の半角英小文字のうち、最初のものだけが抽出されています。
改めて考えてみますと、最初の画像で示した「...」という正規表現も、本来は最初の3文字だけでなく、4~6文字目、さらには7~9文字目にマッチするのですが、最初にマッチしたものを抽出するというREGEXEXTRACT関数の性質により最初の3文字だけが抽出されています。このあたりは(マッチしたものすべてを置き換える)REGEXREPLACE関数の挙動と比べるとわかりやすいかと思います。
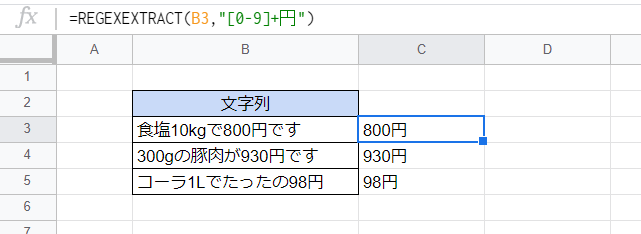
ここでは、それぞれの文字列に1文字以上の半角数字が2か所ずつ含まれていますが、「円」の文字を正規表現に含めることにより、金額部分だけを抽出しています。
C3セル
=REGEXEXTRACT(B3,"[0-9]+円")
「[0-9]+円」は、「1文字以上の半角数字と『円』の字が連なった部分」にマッチします。
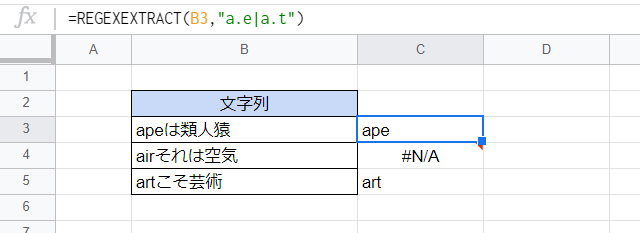
「2文字以上の文字列のいずれか」を指定する場合はパイプライン(|)を使います。
C3セル
=REGEXEXTRACT(B3,"a.e|a.t")
「a.e|a.t」は「『aで始まりeで終わる3文字』か『aで始まりtで終わる3文字』のいずれか」にマッチします。
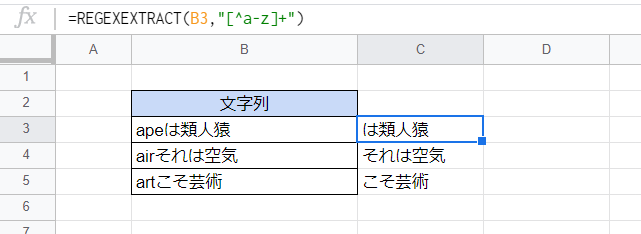
上記のように角カッコ([ ])を用いることで文字を列挙することができますが、この中に「^」を置くことで「~以外の文字」という指定をすることができます。
=REGEXEXTRACT(B3,"[^a-z]+")
「[^a-z]+」は「1文字以上の半角英小文字以外の文字」にマッチします。
アンカーの使用
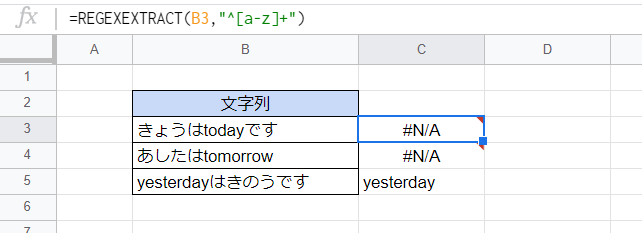
文字列の先頭を表すアンカー「^」を使って、文字列の先頭部分だけを検索して抽出できます(同じ「^」でも上記の「[^a-z]」とは意味が異なるので注意)。
C3セル
=REGEXEXTRACT(B3,"^[a-z]+")
「^[a-z]+」は「文字列の先頭にある1文字以上の半角英小文字」にマッチします。よって文字列の先頭が半角英小文字でない場合は何も抽出されずエラーになります。
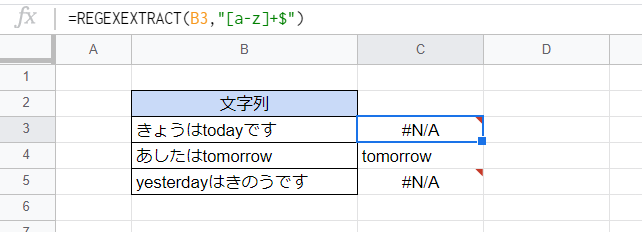
文字列の末尾を表すアンカー「$」を使って、文字列の末尾部分だけを検索して抽出できます。
C3セル
=REGEXEXTRACT(B3,"[a-z]+$")
「[a-z]+$」は「文字列の末尾にある1文字以上の半角英小文字」にマッチします。よって文字列の末尾が半角英小文字でない場合は何も抽出されずエラーになります。
グループ化(カッコ)の使用
マッチした文字列中の一部だけを抽出する
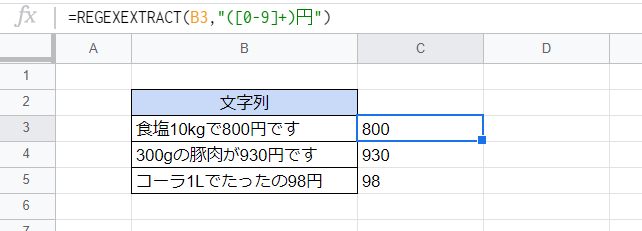
カッコを用いると、正規表現にマッチする部分のうちさらに一部だけを抽出することができます。カッコの外の正規表現は検索に用いられるものの、抽出はされません。
=REGEXEXTRACT(B3,"([0-9]+)円")
「([0-9]+)円」は「1文字以上の半角数字と『円』の字」にマッチしますが、抽出されるのは半角数字の部分のみとなります。
結果的に金額を表す数字だけが抽出されています。
複数のセルに分割して抽出する
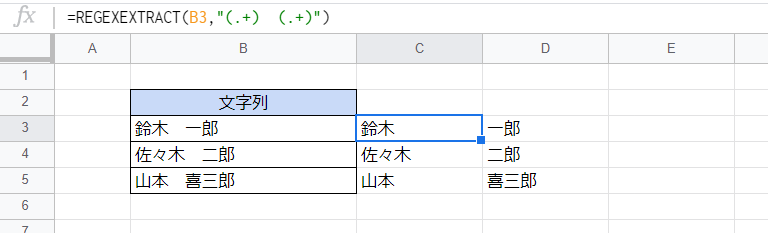
カッコを複数用いると、マッチするそれぞれの部分を複数のセルに分けて抽出することができます。
画像では全角スペースで分けられた苗字と名前を2つのセルに分割しています。
=REGEXEXTRACT(B3,"(.+) (.+)")
全角スペースを挟んで「(.+)」が2か所あります。前者が苗字にマッチし、後者が名前にマッチします。結果はそれぞれC列とD列に表示されます。
ちょっとした応用として「=REGEXEXTRACT(B3,REPT("(.)",LEN(B3)))」とするとB3セルの文字列を1文字ずつ各セルに分割することができます。
2文字以上のORを接続するために用いる(非キャプチャグループ)
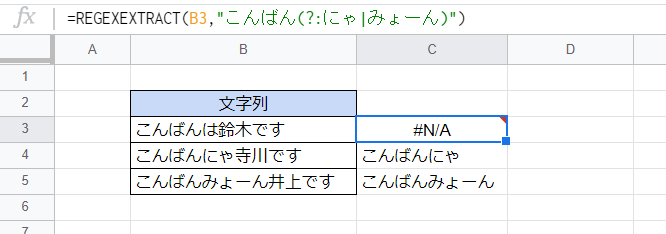
カッコを使うものの、カッコの外も抽出したいという場合にあります。非キャプチャグループと呼ばれます。
=REGEXEXTRACT(B3,"こんばん(?:にゃ|みょーん)")
「(?:にゃ|みょーん)」の部分が非キャプチャグループです。「『こんばん』の後に『にゃ』または『みょーん』が続く部分」を表現すると「こんばん(にゃ|みょーん)」となりますが、カッコを使う関係上、上記の機能により「こんばん」の部分が抽出されなくなります。そこで「こんばん(?:にゃ|みょーん)」とすることにより、全体を抽出することができます。
フラグの使用
フラグとは簡単に言ってマッチングの際のオプション(設定)です。ここでは2つのフラグを紹介します。
大文字と小文字を区別せず抽出する
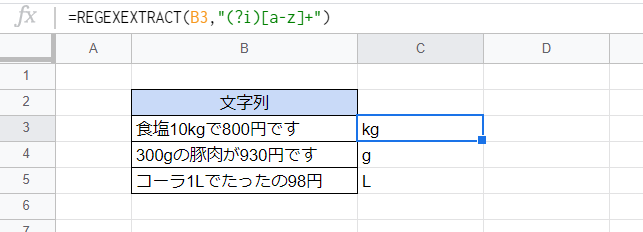
基本的に正規表現では大文字と小文字が区別されますが、それらの区別なしに抽出することができます。
C3セル
=REGEXEXTRACT(B3,"(?i)[a-z]+")
「(?i)」の部分がフラグです。これににより大文字と小文字の区別なく抽出の対象となります。
このケースでは「=REGEXEXTRACT(B3,"[A-Za-z]+")」でも同じ結果になります。単純な抽出であればこのような指定で済みますので、必要性は高くありません。
マルチラインモード
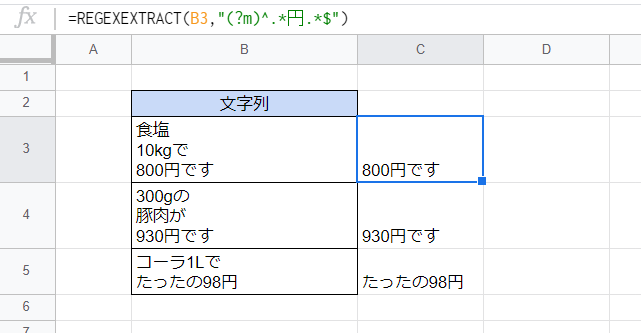
マルチラインモードを用いると、改行を含む文字列の各行の先頭に「^」がマッチし、各行の末尾に「$」がマッチするようになります。
ここではマルチラインモードを用いて、各文字列中の「円」の字を含む行を抽出しています。
C3セル
=REGEXEXTRACT(B3,"(?m)^.*円.*$")
「(?m)」の部分がマルチラインモードを表すフラグです。これにより各行の先頭に「^」が、各行の末尾に「$」がマッチします。さらにが任意の0文字以上の文字列を表す「.*」を組み合わせることで、「^.*円.*$」は「『円』の字を含む行」にマッチすることとなります。
グループ化と波カッコ量指定子の併用
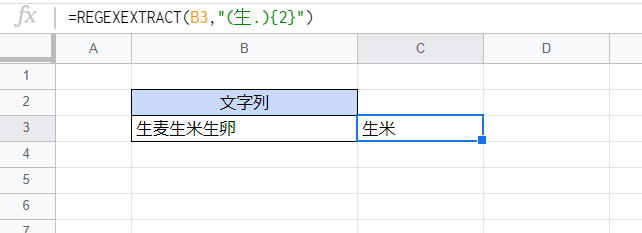
これはオマケですが、カッコによるグループ化と量指定子としての波カッコを併用した場合に、繰り返し部分の全体を抽出しません。
「{i}」の場合はi番目の繰り返し部分のみを、「{i,j}」の場合はj番目の部分のみを抽出します。
=REGEXEXTRACT(B3,"(生.){2}")「(生.){2}」は「『生』で始まる2文字の2回の繰り返し」を表しますので「生麦生米生卵」の中の「生麦生米」にマッチしそうですが、REGEXEXTRACT関数では2番目の繰り返し部分である「生米」だけを抽出します。これを応用すればi番目のマッチを抽出するインデックスとして使用できそうですが、結局のところ正規表現が複雑になり、あまり実用的とは言えないようです。