FIND関数などを併用する方法が知られているものの中間一致(~を含む)・前方一致(~で始まる)・後方一致(~で終わる)の切り替えが面倒なので、ここでは異なる方法を紹介します。
- REGEXMATCH関数を併用することで中間一致・前方一致・後方一致による抽出ができます。
- ワイルドカードを使いたい場合はCOUNTIFS関数を併用する方法もあります。
手順
REGEXMATCH関数を使う方法
「~を含む」という条件(中間一致)

画像ではB列に市町村の名前が記録されています。
これに対しD3セルに次のような式を入力することで、「山」の字を含む市町村名を抽出しています。
D3セル
=FILTER(B3:B12,REGEXMATCH(B3:B12,"山"))
第2引数(抽出条件)を「REGEXMATCH(B3:B12,"山")」としています。
REGEXMATCH関数は正規表現にマッチするかどうかを判定する関数ですが、指定した文字列に一部でもマッチすればTRUEを返すので、メタキャラクタ(記号)を含めることなく中間一致による抽出ができるのがメリットです。
「~で始まる」という条件(前方一致)

REGEXMATCH関数は正規表現に対するマッチングを判定しますので、前方一致による抽出も容易です。
ここでは次のような式により「川」の字で始まる市町村名を抽出しています。
D3セル
=FILTER(B3:B12,REGEXMATCH(B3:B12,"^川"))
正規表現では「^」は文字列の先頭を表し、よって「^川」は「文字列の先頭にある『川』」にマッチします。これをFILTER関数と組み合わせることで「川」の字で始まる文字列を抽出できます。
「~で終わる」という条件(後方一致)
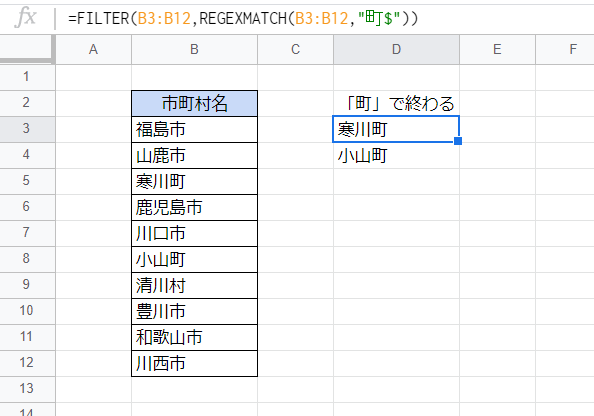
後方一致による抽出の例です。
ここでは次のような式により「町」の字で始まる市町村名を抽出しています。
D3セル
=FILTER(B3:B12,REGEXMATCH(B3:B12,"町$"))
正規表現では「$」は文字列の末尾を表し、よって「町$」は「文字列の末尾にある『町』」にマッチします。これをFILTER関数と組み合わせることで「町」の字で終わる文字列を抽出できます。
COUNTIFS関数を使う方法
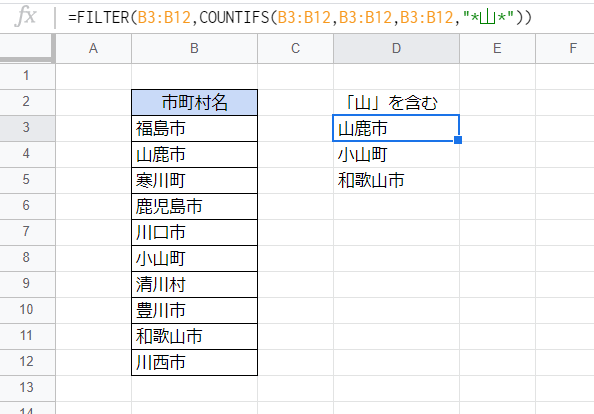
どうしてもワイルドカード(*や?)を使って抽出したいという方のための方法です。
画像では次のような式で、上記の最初の例と同じく「山」の字を含む市町村名を抽出しています。
D3セル
=FILTER(B3:B12,COUNTIFS(B3:B12,B3:B12,B3:B12,"*山*"))
抽出条件がやや難解ですが、この「COUNTIFS(B3:B12,B3:B12,B3:B12,"*山*")」は「各行に「山」を含む文字列が何個あるか(0または1)」という配列を返すため(この場合は{0;1;0;0;0;1;0;0;1;0})、FILTER関数により配列中の「1」に対応する文字列(「山」を含む文字列にほかなりません)が返されます。もちろん同様に前方一致、後方一致も可能です。
なお、この方法については次の記事でも触れています。