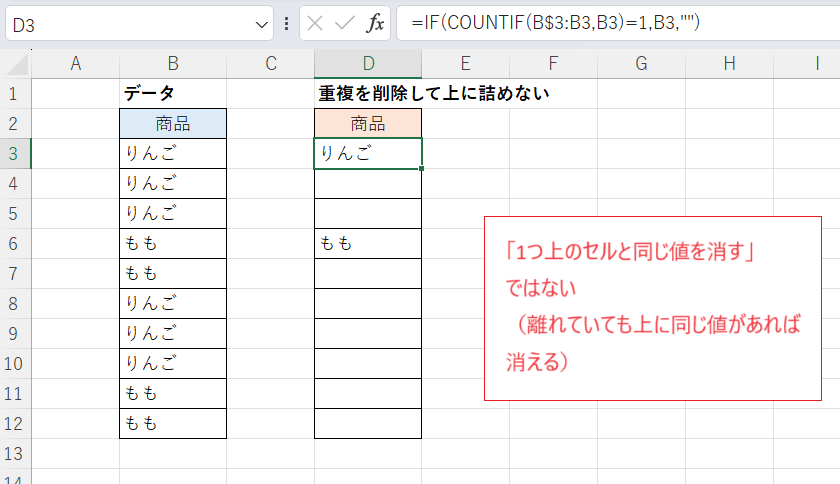
ただし「重複を削除する」のは「1つ上と同じ値を削除する」こととは異なるので注意してください。
データが1列の場合
次の画像では、B3:B12の範囲に対象となるデータが記録されています。
そこでD3セルに次の式を入力します。
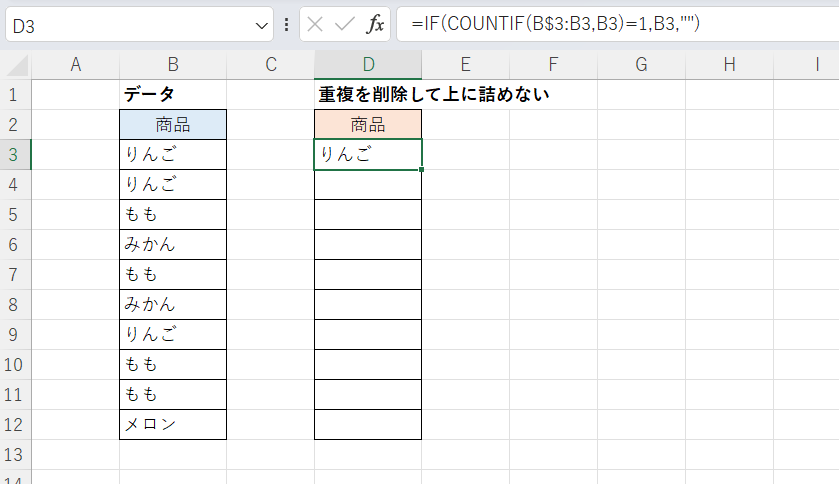
D3セル
=IF(COUNTIF(B$3:B3,B3)=1,B3,"")
そして式をB12までフィルコピーすると、重複する値(のうち2番目以降に出現するもの)が削除され、削除された値の位置には空白(空文字列)が残ります。
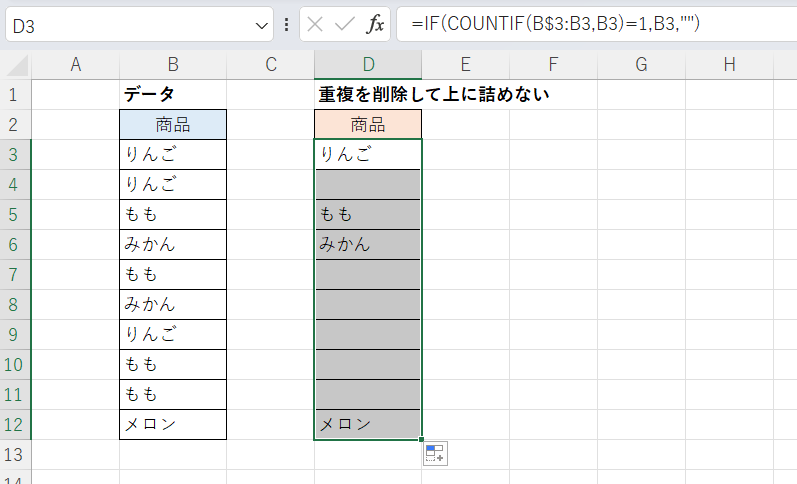
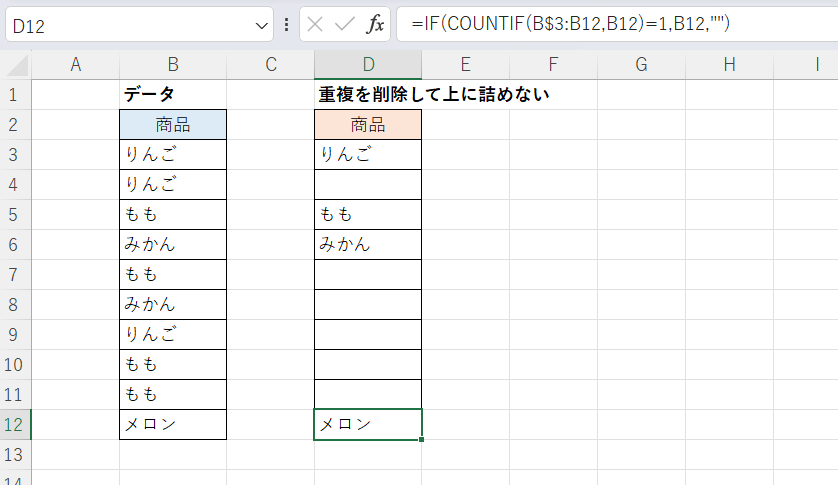
D12セルの式を見ると「=IF(COUNTIF(B$3:B12,B12)=1,B12,"")」となっています。同様にD11セルは「=IF(COUNTIF(B$3:B11,B11)=1,B11,"")」となっています。
つまりD3からD12の各セルでは「B列の同じ行にある値を(B3セルから同じ行のセルまでの範囲で)カウントし、1だったら(その値は初めて出現していることになるので)そのまま表示し、そうでなかったら空文字列を表示する」ということをしています。
注意点:「1つ上のセルと同じ値を削除する」ではない
本記事ではUNIQUE関数と同様に「範囲内で重複する値を1つだけ残す」ということを行っています。
次の画像はわかりやすいようにデータの内容を変えたものですが、このように一度途切れた値が再度出現した場合についてもすべて削除され空白になります。
1つの式で実現する
こちらでは上記と同じ内容をD3セルの1つの式だけで実現しています。
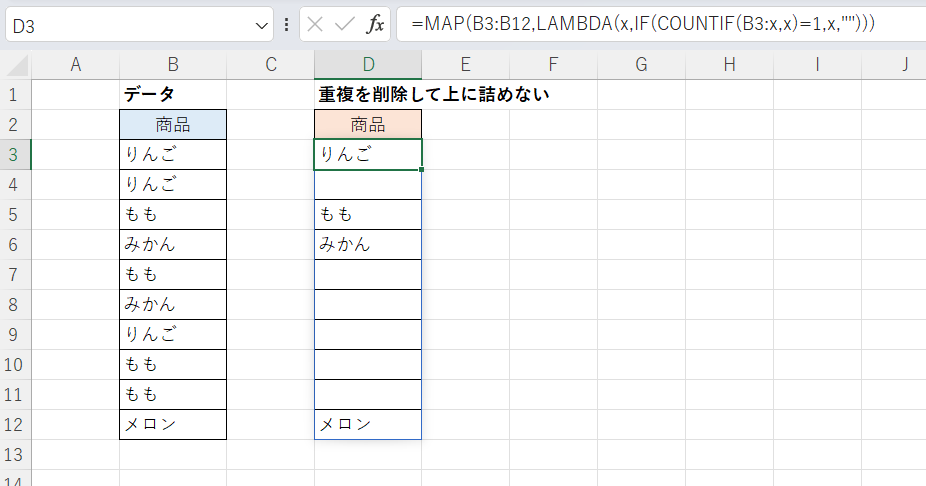
D3セル
=MAP(B3:B12,LAMBDA(x,IF(COUNTIF(B3:x,x)=1,x,"")))
式の見た目は異なりますが考え方は最初の例と同様です。
具体的にはB3:B12の範囲をxと名付け、その1つ1つについてCOUNTIF関数を実行しています。つまり次の10個の式を実行しています。
IF(COUNTIF(B3:B3,B3)=1,B3,"") IF(COUNTIF(B3:B4,B4)=1,B4,"") ・・・ IF(COUNTIF(B3:B12,B12)=1,B12,"")
上記の式中でCOUNTIF関数の第1引数(検索範囲)を「B3:x」としているところがポイントで、検索範囲が次第に拡大されます。
データが複数列(行単位で重複削除)の場合
こちらはデータが2列の例です。
重複する行(2つの列の値がともに一致する行)の値を削除し空白に置き換えるものとします。
まずD4セルに次のように入力します。
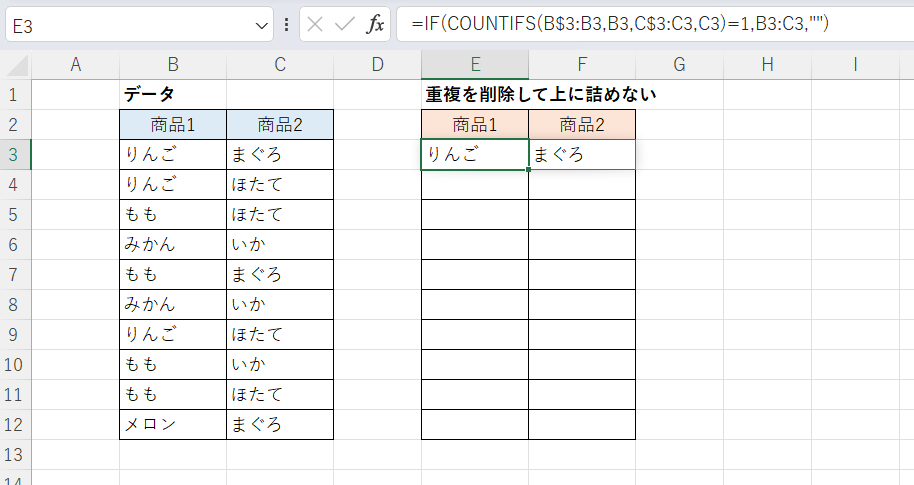
D4セル
=IF(COUNTIFS(B$3:B3,B3,C$3:C3,C3)=1,B3:C3,"")
これも基本的には最初の例と同様ですが、COUNTIFSを使うことにより行単位で一致をチェックしています。
COUNTIFを2つ使ってB列の値とC列の値を別々にカウントするようなやり方だとおかしな結果になります。
D12までフィルコピーすると完成です。
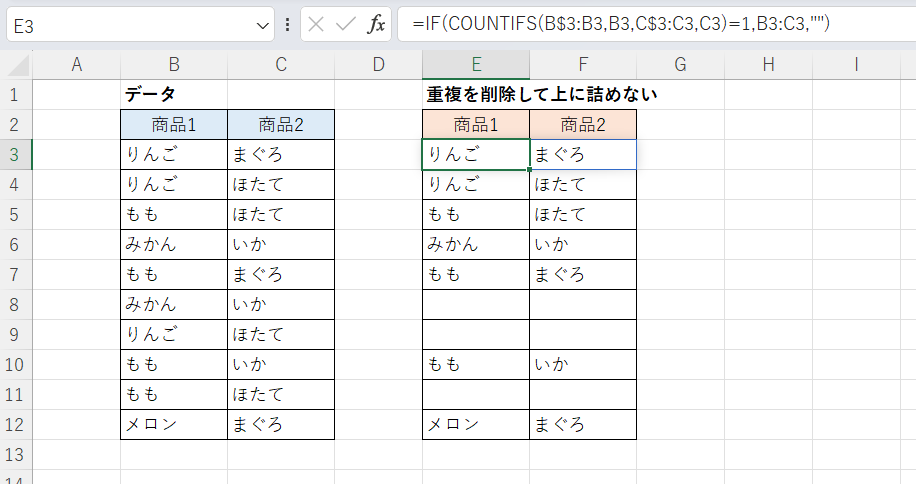
ちなみに次のような式にすれば1つの式で済みそうですが、エラーとなるので(「x:y」という出力ができないのが問題)別のアプローチを考える必要があります。
エラーになる式
=MAP(B3:B12,C3:C12,LAMBDA(x,y,IF(COUNTIFS(B3:x,x,C3:y,y)=1,x:y,"")))