- メニュー操作による方法とUNIQUE関数を使う方法で、データの重複を削除することができます。
- 微妙に機能が異なるのが注意点です。
メニュー操作による方法
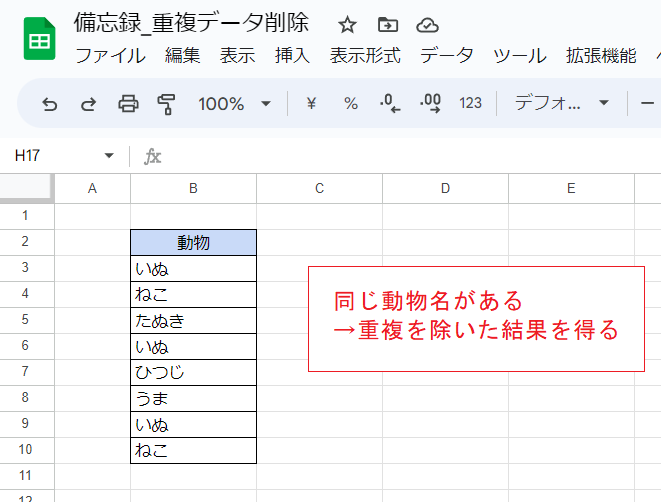
B列に小さな表があり、動物の名前が並んでいます。
名前には重複するものがありますが、その重複を除いていずれも1つだけにしてみます。
表の中のいずれかのセルを選択した状態で、メニューから「データ」→「データクリーンアップ」→「重複を削除」と選択します。
データは全体を選択しておいてもいいですが、中途半端に複数のセルを選んでしまうとそこだけが対象になってしまうのでそれは避けてください。

ダイアログが現れます。
対象範囲が自動選択されて示されますので確認のうえ「重複を削除」をクリックします。
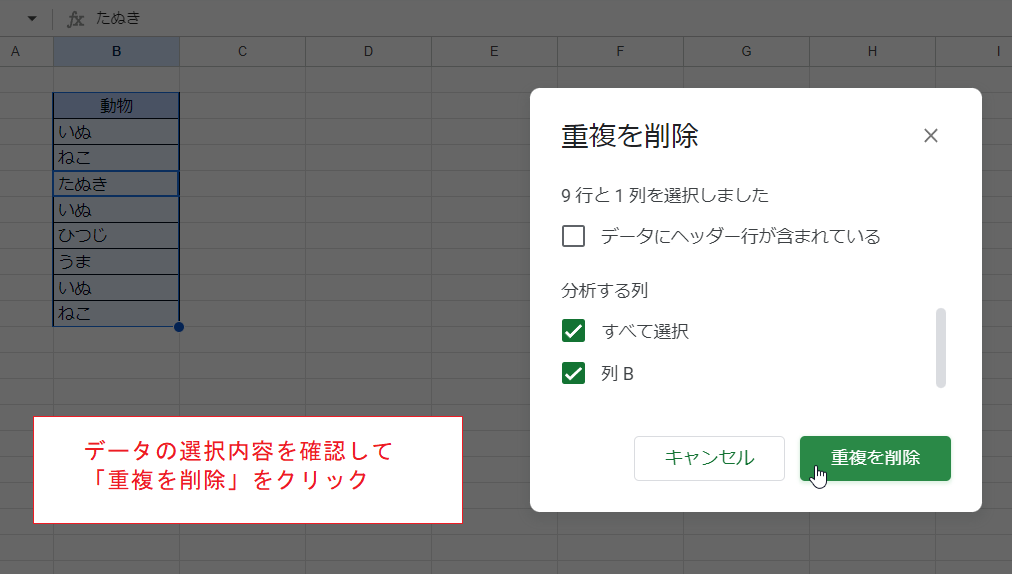
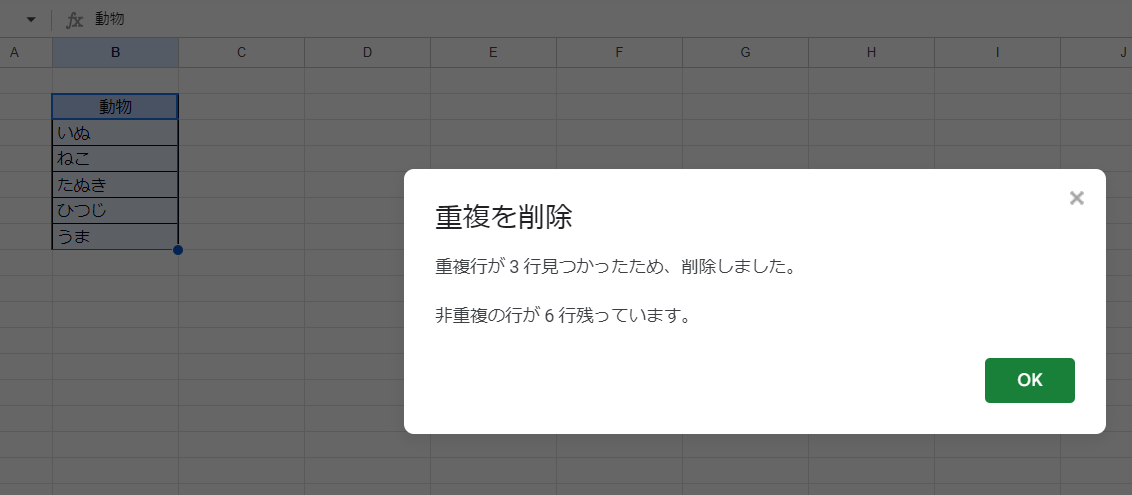
重複が除かれました。
罫線も削除されて表が小さくなっていますが、セルの削除とは異なり表の下方にある値が上方に詰められることはありません。
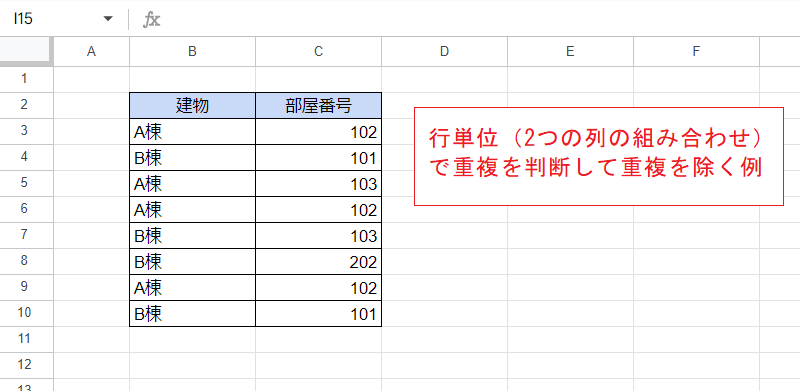
こちらは複数の列を対象とする例です。
この場合、個々のセルの値ではなく複数の列の組み合わせ(表内の行全体)で重複が判定され、行の重複が除かれます。
最初の例と同様にしてメニューから「重複の削除」を実行したところです。
「分析する列」として2つの列が(自動的に)選択されています。
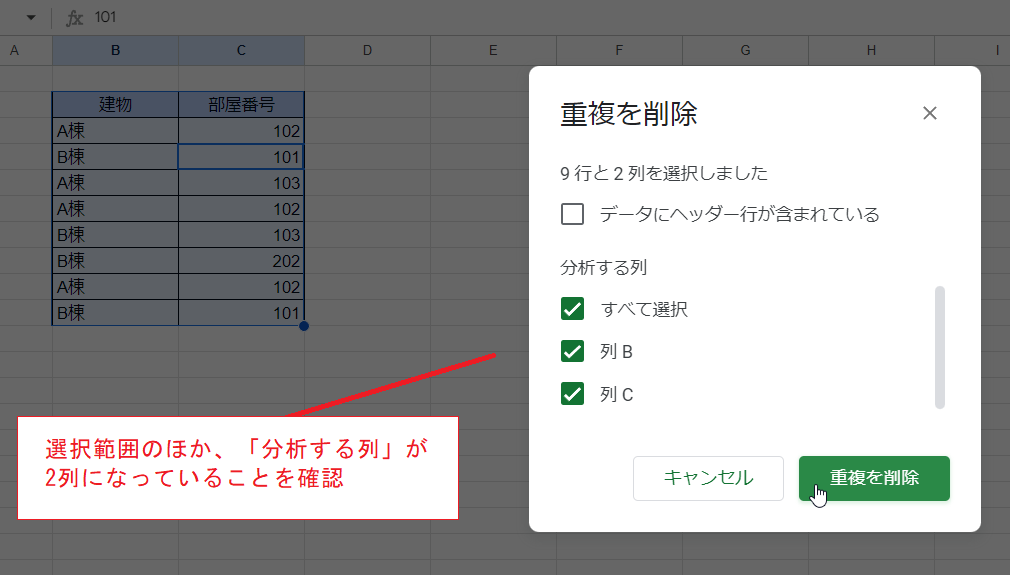
実行結果は次のとおりとなります。
個々のセルの値でみれば重複が残っていますが、2つの列の組み合わせでみると重複するもの(行)が残っていないことがわかります。

こちらは3つの列からなるデータの例ですが、「顧客番号」と「氏名」の2つの列の組み合わせで重複を判定して重複するものを除き、「住所」についてはたとえ異なる値が記録されていても1つだけ残してムリヤリまとめてしまおう、という例です。
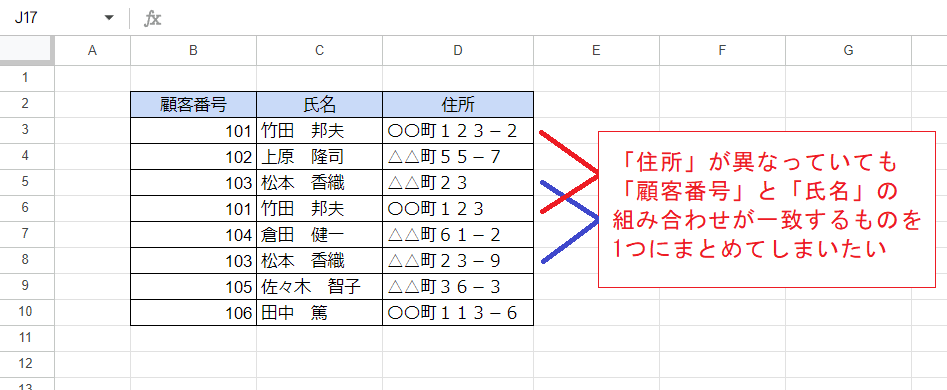
上記の例と同じようにメニューから「重複の削除」を実行したところです。
ここで「分析する列」として「列B」と「列C」のチェックだけを残します。
そして「重複の削除」をクリックすると……
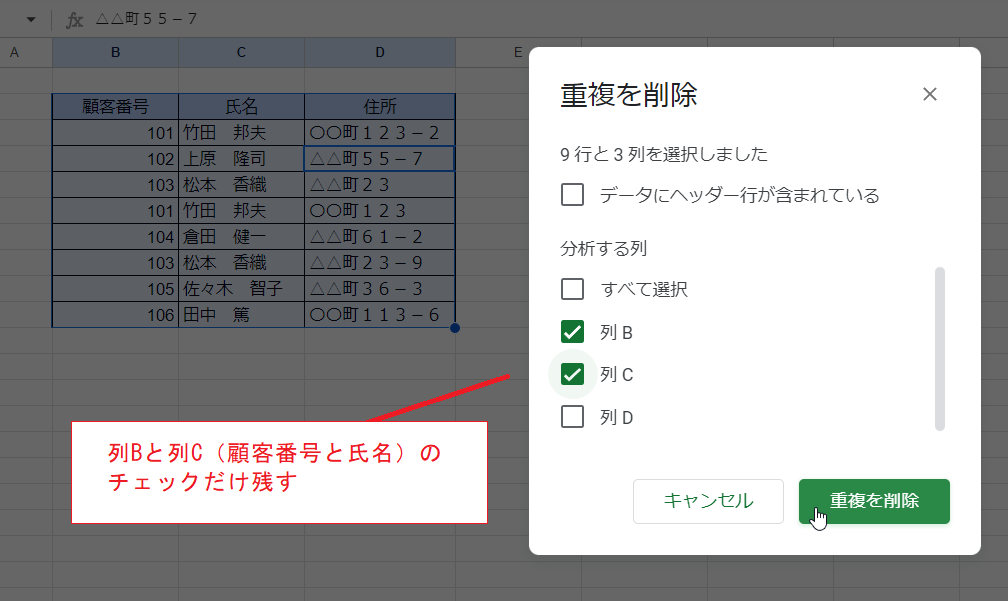
2つの列だけで重複が判定され、除いた結果が得られました。
「住所」だけが異なる場合にその値はどうなるかですが、最も上にあった値だけが残ります。
多数決とか値そのもののもっともらしさから選ぶといったものではないので、名寄せ機能としては微妙かもしれません。

UNIQUE関数による方法
こちらは関数による方法です。
元のデータはそのままで、重複が除かれたデータを別の範囲に出力できます。
画像ではB3:B10の範囲のデータについて、UNIQUE関数を使って重複を削除した結果を出力しています。
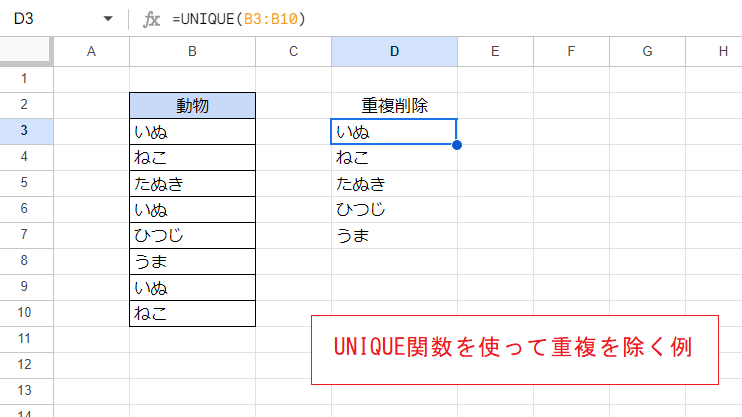
D3セル
=UNIQUE(B3:B10)
UNIQUE関数の引数として範囲を指定するだけで、重複を除いた結果を出力できます。
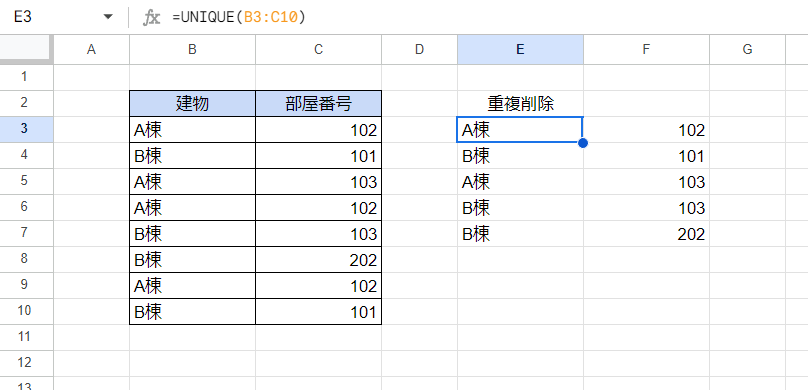
次の画像では複数の列からなる範囲(B3:C10)を指定しています。
2つの列の組み合わせ(表内の行全体)で重複が判定され、行の重複が除かれています。
備考
2つの方法における機能の相違点は次のとおりです。
- メニュー操作の場合、英大文字と英小文字は区別されず重複とみなされますが、全角文字と半角文字は区別されます。一方でUNIQUE関数の場合はいずれも区別されます。
- メニュー操作の最後の例でみた「分析対象以外の列についても値を削除して1つだけ残す」という機能がUNIQUE関数にはありません。一方で「列単位で重複を除く」という機能と「1つしかないデータだけを残す」という機能があります。UNIQUE関数の詳しい機能については次の記事で紹介しています。