これらはExcelにも導入され、UNIQUE関数の引数の仕様はGoogleスプレッドシートに逆輸入されています。
- UNIQUE関数により、値の重複を除いた結果を得ることができます。
- 基本的に行全体(複数の列全体)で重複が判定され、行単位で重複が除かれるので注意が必要です。
構文
UNIQUE関数の基本的な機能は「値の重複を除いた結果を出力する」というものです。
構文は次のとおりで、最大3つの引数を指定できます。
UNIQUE(範囲[, 行で処理, 重複なし])
| 値 | 効果 |
|---|---|
| FALSE | 行の重複を除く(既定値) |
| TRUE | 列の重複を除く |
| 値 | 効果 |
|---|---|
| FALSE | 重複している値(行・列)を1つにまとめる(既定値) |
| TRUE | もともと1つしかない値(行・列)だけを残す |
第1引数のみが必須であとは任意です。
以下では第1引数だけを指定した単純な例と、第2・第3引数の設定例を紹介します。
基本的な使用例
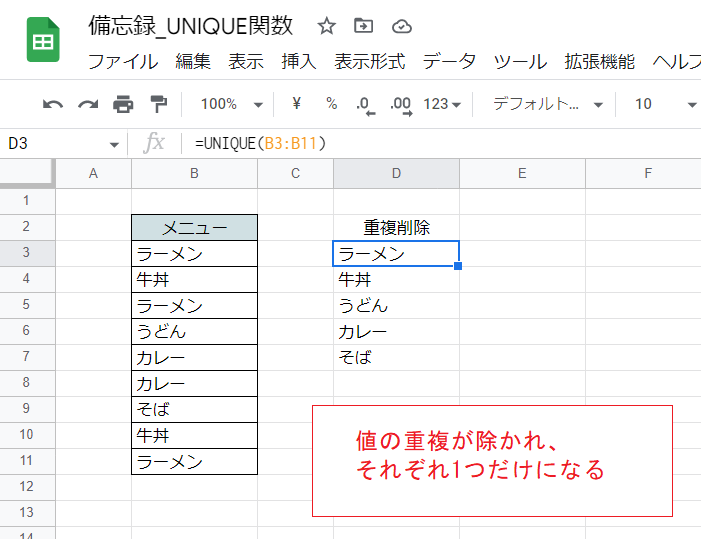
もっとも単純な例でです。
D3セルに式を入力し、B3:B11の範囲に記録された値から重複を除いた結果を得ています。
3つある「ラーメン」、2つずつある「牛丼」「カレー」がそれぞれ1つだけになって出力されているのがわかります。
D3セル
=UNIQUE(B3:B11)
対象となる範囲を指定するだけでOKです。なお、値の並び順は初出順となります。
次の画像はD3セルに「=UNIQUE(B3:C9)」と入力し、複数の列にわたる範囲を指定した例です。
結果は複数の列となっています。7つあった行は2つ減って5つになっていますが、個々のセルの値を見ると「A棟」「B棟」「101」「102」という値がいずれも複数残っています。
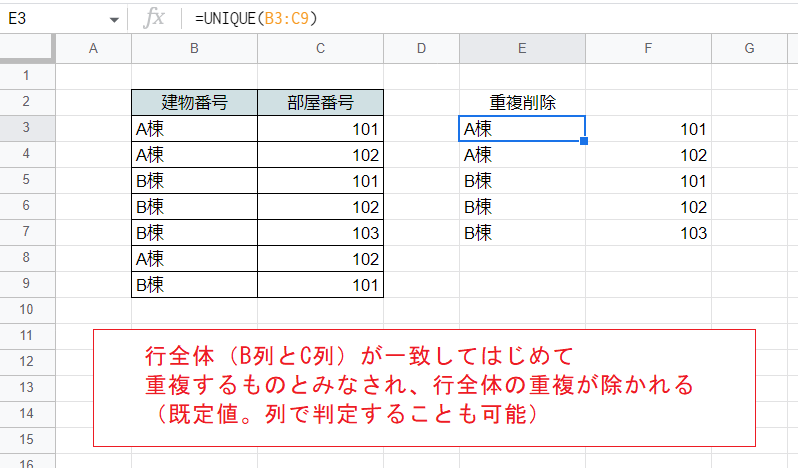
しかし、行全体(2つの列の組み合わせ)で見れば、重複する行は残っていないことがわかります。
このようにUNIQUE関数では行全体で重複を判定し、重複する行を1つにまとめます。SQLでDISTINCTとかGRUOUP BY句を指定したとき(Accessのグループ化)と同じ結果で、行全体を1まとまりのデータ(レコード)として捉えるデータベース的な考え方が反映されています。
従って、セル単位で重複を除こうとして複数列の範囲を指定しても当然うまくいきません。
次の例では指定した範囲の内容がそのまま戻ってくる結果となっています。
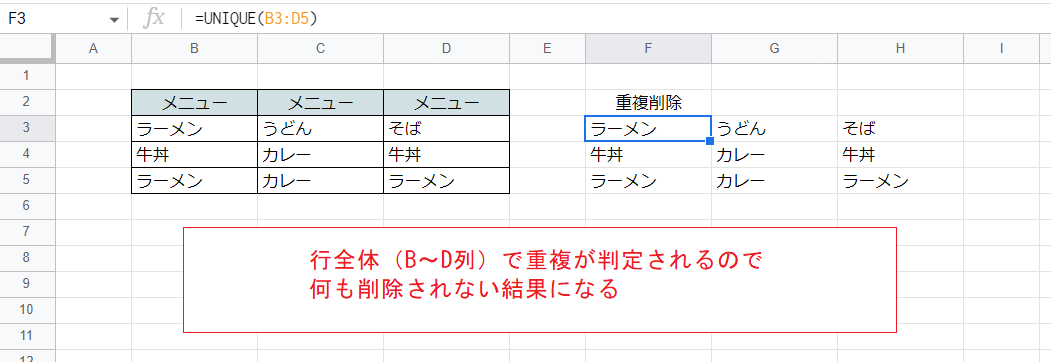
このようなときはFLATTEN関数を使ってセルを縦1列に並べてからUNIQUE関数を適用するのが適当です。
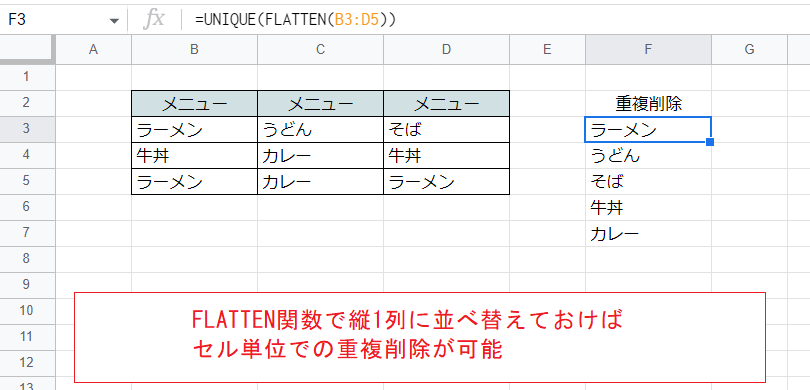
F3セル
=UNIQUE(FLATTEN(B3:D5))
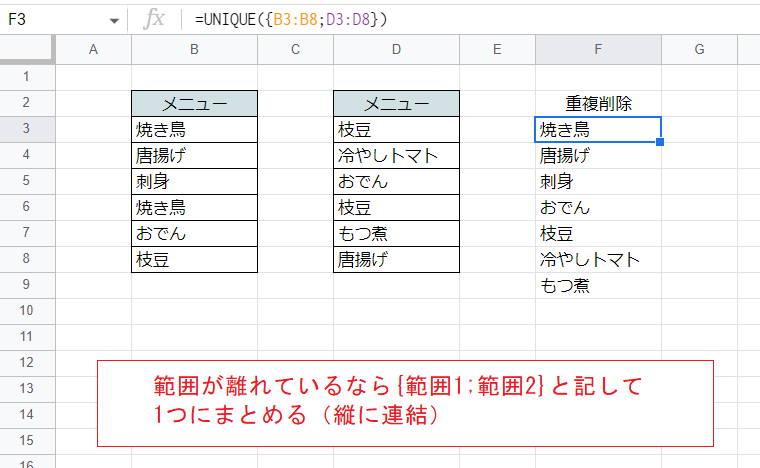
また、対象とする範囲が飛び飛びになっている場合は「{範囲1;範囲2}」の書式を使って縦に重ね、1つの範囲にまとめるのが適当です。
F3セル
=UNIQUE({B3:B8;D3:D8})「{範囲1;範囲2}」は2つの範囲を縦に重ねる記法です。
一方で、「{範囲1,範囲2}」の書式(カンマを使う)だと異なる結果になります。これは2つの範囲を横に並べる記法だからです。
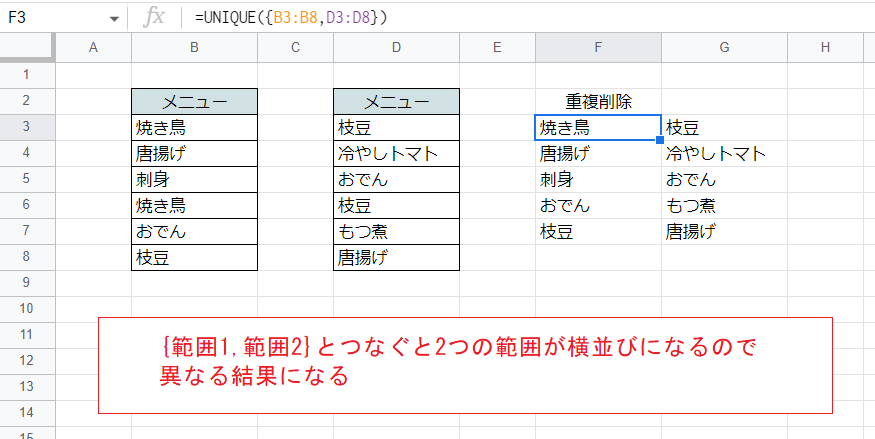
F3セル
=UNIQUE({B3:B8,D3:D8})この場合、2つ目の画像の例と同じく行全体(2つの列の全体)で重複を判定して削除しますので、「焼き鳥」「枝豆」からなる2つの行が重複していると判断され、1つにまとめられます。
第2引数(行で処理)の効果と使用例
第2引数には次の2種の値を指定でき、省略した場合はFALSEを指定したものとみなされます。
| 値 | 効果 |
|---|---|
| FALSE | 行の重複を除く(既定値) |
| TRUE | 列の重複を除く |
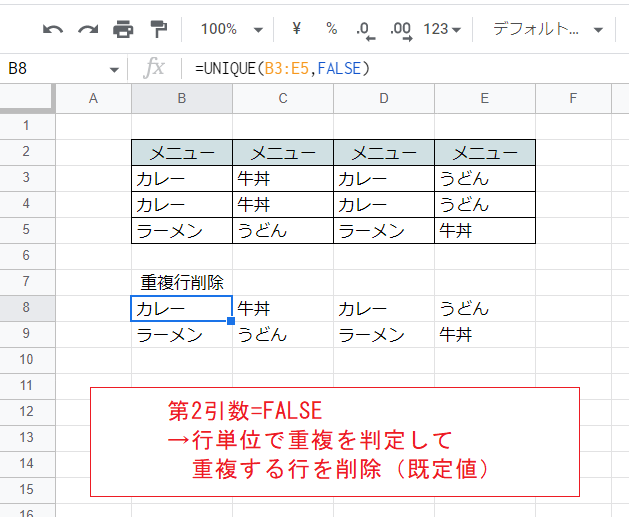
こちらはFALSEとした例です(既定値なので省略しても同じ結果になります)。
この場合、第1引数で指定した範囲について、行単位で(行全体が重複しているかどうかで)重複を判定し削除します。
「カレー」「牛丼」「カレー」「うどん」という行が2つあるので、これらが1つにまとめられて出力は2行になっています。
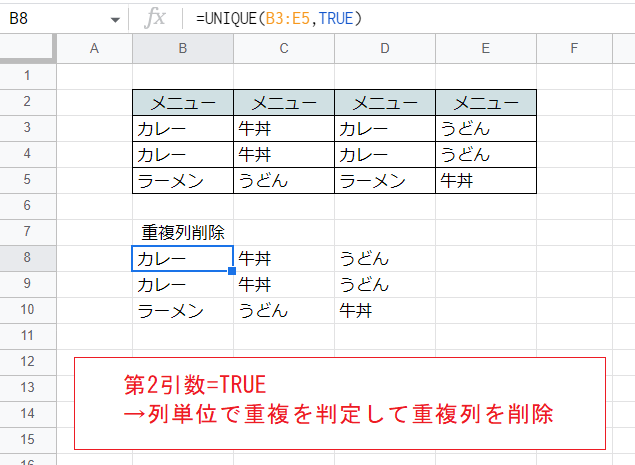
一方で、こちらはTRUEとした例です。
この場合、第1引数で指定した範囲について、列単位で(列全体が重複しているかどうかで)重複を判定し削除します。
「カレー」「カレー」「ラーメン」と縦に並んだ列が2つあるので、これらが1つにまとめられて出力は3列になっています。
第3引数(重複なし)の効果と使用例
第3引数には次の2種の値を指定でき、省略した場合はFALSEを指定したものとみなされます。
| 値 | 効果 |
|---|---|
| FALSE | 重複している値(行・列)を1つにまとめる(既定値) |
| TRUE | もともと1つしかない値(行・列)だけを残す |
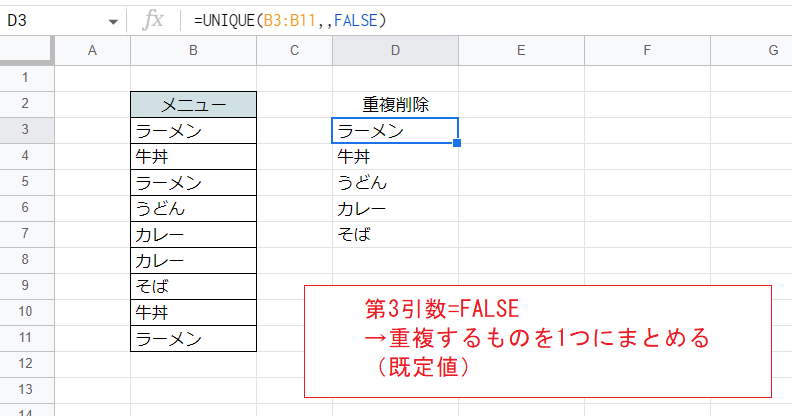
こちらはFALSEとした例です(既定値なので省略しても同じ結果になります)。
この場合、重複している行(第2引数がTRUEの場合は列)が1つにまとめられます。
結果として最初の画像と全く同じ結果になります。
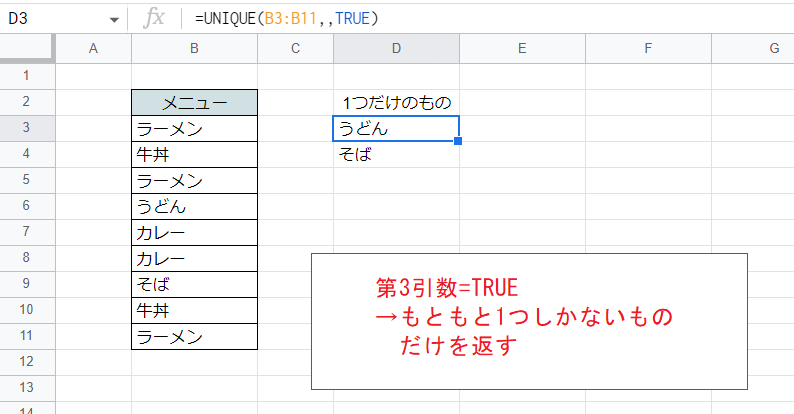
一方でこちらはTRUEとした例です。
この場合、もともと1つしかない行(第2引数がTRUEの場合は列)だけが残ります。
本来の意味でユニーク(唯一)といえますが、ちょっと異質な意味合いになっています。
注意点
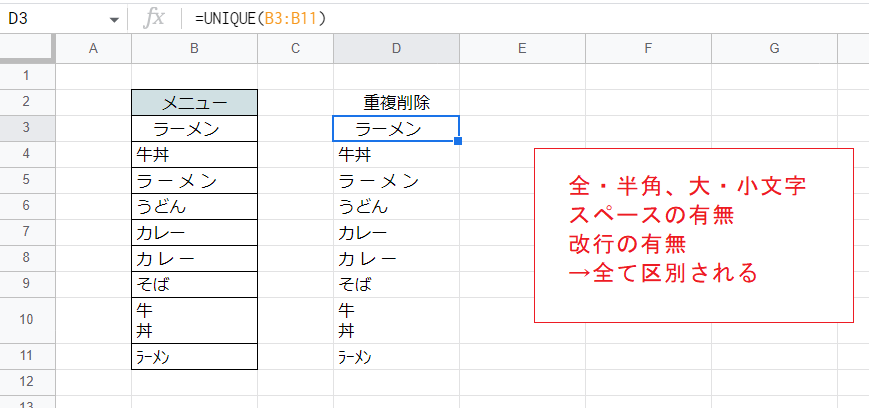
UNIQUE関数では全角や半角、大文字と小文字、空白(スペース)の有無などは別物として区別されます。よってUNIQUE関数で雑にデータクリーニング的なことをしようと思っても難しいです。
応用例
項目別の集計に利用することができます。
次の記事で例を紹介しています。
次の記事では、第3引数をTRUEとして使う、少し変わった例を紹介しています。