抽選の内容
次の画像のように各参加者(応募者)に口数(1以上)が設定され、さらに当選者数も設定されているものとします。

抽選内容は次のようなものです。
- 各参加者の当選確率を口数に応じて(多ければ多いほど)上昇させる
- 各参加者は二重・三重に当選することはなく、自身が当選するかしないかの2通りしかないものとする
よくありそうな内容ですが、1.で「口数に応じて(≒比例して)当選しやすくする」といいつつ2.により「参加者数と当選者数が等しい場合は口数に関わらず全員当選しなければおかしい」となる辺りが考えどころです。
そこで抽選内容の趣旨を踏まえたうえで、具体的に以下のような抽選を行うものとします。
- それぞれの「口」にランダムに順位をつける
- 最上位の「口」を持っている参加者を1位当選者とし、1位当選者が持つ「口」を以降の抽選から除く
- 残った「口」のうち最上位のものを持っている参加者を2位当選者とし、2位当選者が持つ「口」を以降の抽選から除く(以下同様)
口数に応じた抽選の方法
まずはG列に作業列を設け、各参加者の「口数の累計値」を求めます。
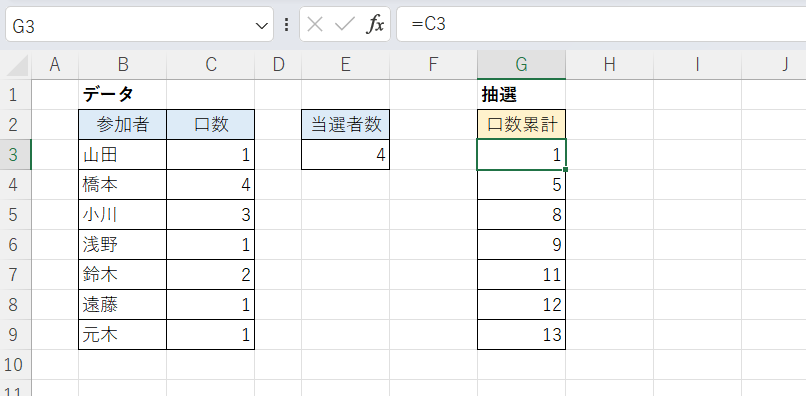
G3セル
G4セル(下方にフィルコピー)
=C3 =G3+C4
この列は次のようなことを意味し、以降の抽選の基礎となります。
- 最初の参加者「山田」は番号1の「口」を持っている
- 次の参加者「橋本」は番号2~5の4つの「口」を持っている
- 次の参加者「小川」は番号6~8の3つの「口」を持っている(以下同様)
次にH3セルに次のような式を入力します。これが実質的な抽選となります。

H3セル
=SORTBY(SEQUENCE(SUM(C3:C9)),RANDARRAY(SUM(C3:C9)))
1から「口数の合計」までの整数をランダムに並べ替える式です。
これでそれぞれの「口」に順位をつけています。
(以降では上記の抽選結果が変化しないよう、H列で値の貼り付けを行ったうえで進めています)
続いてI3セルに次のような式を入力し、それぞれの「口」を持つ参加者を表示させます。
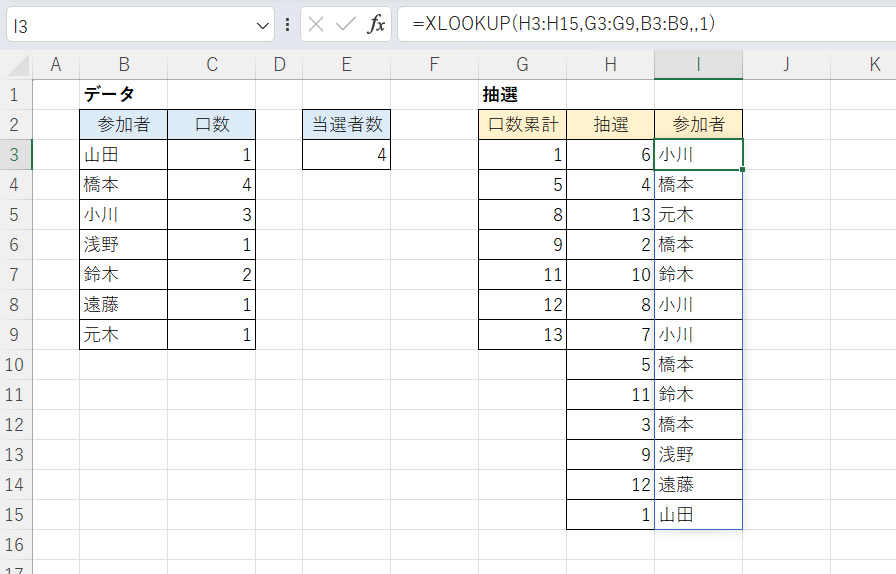
I3セル
=XLOOKUP(H3:H15,G3:G9,B3:B9,,1)
XLOOKUP関数を使い第5引数(一致モード)を「1」(完全一致検索をし、見つからなければ検索値より大きい直近の値を検索する)としています。
これで例えば2番から5番までの4つの「口」は参加者「橋本」にマッチするものとして「橋本」の名前が抽出されるというわけです。
最後にJ3セルに次のように入力し、設定した数(4人)の当選者を確定させます。
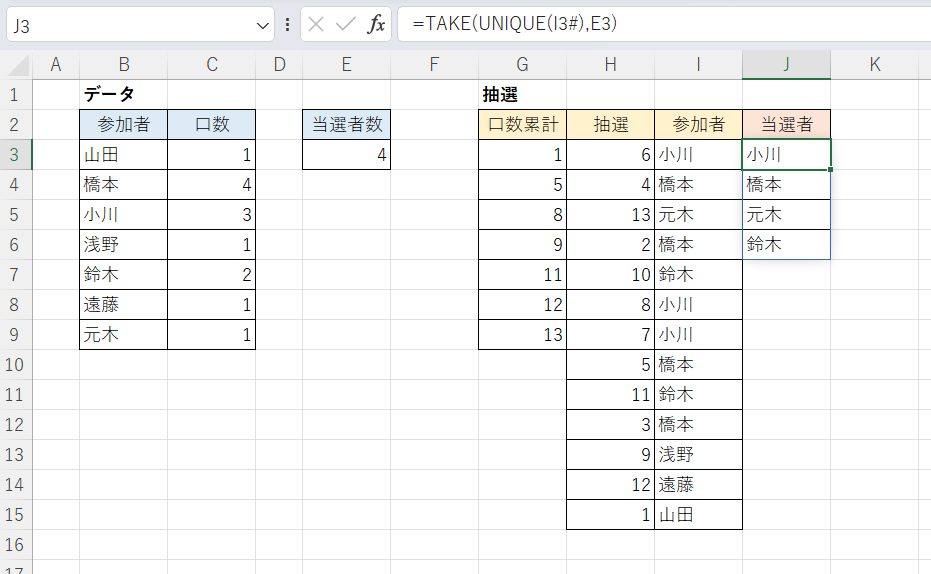
J3セル
=TAKE(UNIQUE(I3#),E3)
スピル演算子(#)を使っていますが「=TAKE(UNIQUE(I3:I16),E3)」としても同じです。
UNIQUE関数を使うことでI列の氏名の重複が除かれ初出順で抽出されることがポイントです。これで冒頭に記した抽選の考え方に沿った結果が得られます。第1位当選者(小川)を除いたうえで累計値を割り振りし直して再抽選…とした方が納得感があるかもしれませんが、直近で見つかる別の者を2位、3位…と決めていった方が早いというわけです。この辺りは物理的に抽選を実施する場合と同じです。
全体的に新しい関数に頼りましたがRANDやMATCHなどを使って同じ結果を得ることも可能です。
一つの式で実行する場合
以上の内容を1つの式にまとめて実行すると次のようになります。

G3セル
=TAKE(UNIQUE( XLOOKUP(SORTBY(SEQUENCE(SUM(C3:C9)),RANDARRAY(SUM(C3:C9))),SCAN(0,C3:C9,LAMBDA(x,a,x+a)),B3:B9,,1) ),E3)
「SCAN(0,C3:C9,LAMBDA(x,a,x+a))」で口数の累計値の算出を行っています。あとは上記の手順で使った関数をそのままつなげています。