さまざまなパターンについて、MID/FIND関数を使う方法及びTEXTAFTER関数を使う方法をそれぞれ紹介します。
特定の文字以降を抽出する
「特定の文字のうち最初のもの」以降の部分を抽出する例です。
まずはMID/FIND関数を使う方法です。
次の画像ではB3:B6セルに対象となる文字列が記録されています。C3セルにMID/FIND関数を使った式を入力しC6までフィルコピーすることで、最初の"特定の文字"である「☆」以降を抽出しています。
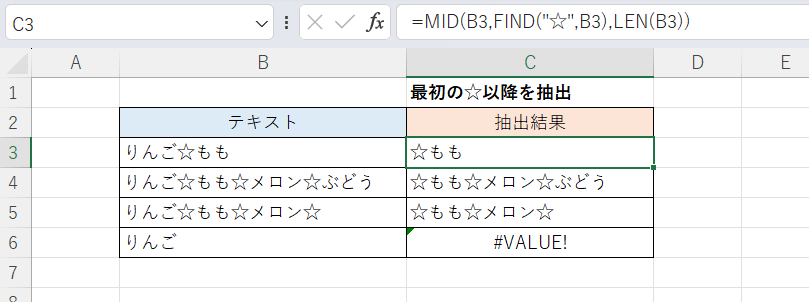
C3セル(下方にフィルコピー)
=MID(B3,FIND("☆",B3),LEN(B3)) RIGHT関数(右からn文字を抽出する)を使う方法も考えられますが、本記事ではMID関数(n文字目以降を抽出する)を使っています。
「FIND("☆",B3)」で文字列中の最初の「☆」の位置を特定し、それをMID関数の第2引数(抽出開始位置)としています。第3引数(抽出文字数)についてはとにかく大きい数字を指定しておけば文字列の最後まで抽出できるので「1000」などとする方法もあるのですがちょっと乱暴なので「LEN(B3)」つまり文字列の文字数としています。これで確実に最後まで抽出できます。
特定の文字「☆」が含まれない場合は#VALUE!エラーとなります。
次の画像ではTEXTAFTER関数を使って同じ抽出をしています。

C3セル(下方にフィルコピー)
="☆"&TEXTAFTER(B3,"☆")
TEXTAFTER関数を用いて、第1引数に対象文字列(B3)を、第2引数に「"☆"」を指定しています。
ただしこれで抽出されるのは指定した文字より後の部分だけなので先頭に「"☆"&」をつけて結果的に「☆」以降を抽出した結果を得ています。
TEXTAFTER関数は使えるバージョンが限られるものの、以降の(複雑な)ケースでも簡単に抽出ができるのでおすすめです。
なお「☆」が含まれない場合は#N/A!エラーとなります。対象が空白の場合に#VALUE!エラーになることがありますが、どうせエラーですので詳しくは省略します。
特定の文字より後を抽出する
「特定の文字のうち最初のもの」より後の部分を抽出する例です。
まずはMID/FIND関数を使う方法です。

C3セル(下方にフィルコピー)
=MID(B3,FIND("☆",B3)+1,LEN(B3))基本的には一番最初の例と同様ですが、抽出の開始位置が「『☆』の位置の1つ後」となるので「FIND("☆",B3)+1」としています。
こちらはTEXTAFTER関数を用いる方法です。
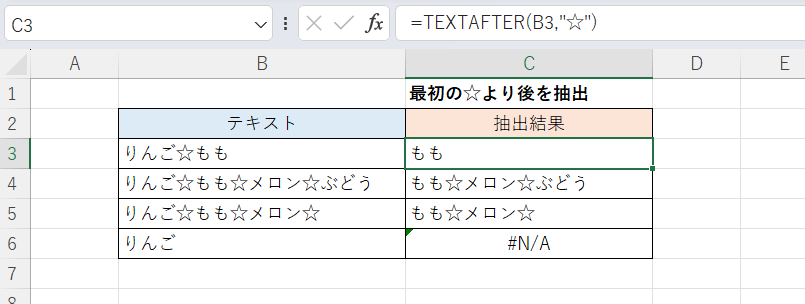
C3セル(下方にフィルコピー)
=TEXTAFTER(B3,"☆")
対象となる文字列と特定の文字を指定するだけで簡単に抽出ができます。
n番目のもの以降を抽出する
次の画像では、MID/FIND関数を使って、2番目の「☆」以降を抽出しています。
2番目の「☆」が存在しない場合は#VALUE!エラーとなります。

C3セル(下方にフィルコピー)
=MID(B3,FIND("☆",B3,FIND("☆",B3)+1),LEN(B3)) MID関数の第2引数(抽出開始位置)を「FIND("☆",B3,FIND("☆",B3)+1)」としています。一見奇妙ですがこれで2番目の「☆」の位置が求められます。
なぜかというとFIND関数の第3引数として「検索開始位置」を指定することができ、これを「FIND("☆",B3)+1」とすることで最初の「☆」の次の位置から検索を開始できるからです。
ただし関数の入れ子(ネスト)となるため3番目、4番目となると式が長く複雑になるのが問題で、5番目とか10番目を指定するには実用的なやり方ではありません。
ちなみに3番目以降を抽出する場合は「=MID(B3,FIND("☆",B3,FIND("☆",B3,FIND("☆",B3)+1)+1),LEN(B3))」となります。
続いてTEXTAFTER関数を使う方法です。
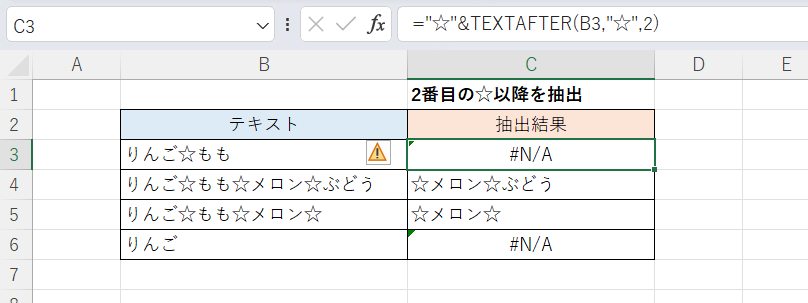
C3セル(下方にフィルコピー)
="☆"&TEXTAFTER(B3,"☆",2)
第3引数として「2」と指定するだけで、指定した特定の文字「☆」のうち2番目より後の部分を抽出できます。もちろん3番目以降も同様で、とても簡単です。
ただしn番目の特定の文字自体は抽出に含まれないので「"☆"&」で付け加えています。
n番目のものより後を抽出する
MID/FIND関数を使って、2番目の「☆」よりも後の部分を抽出する方法です。
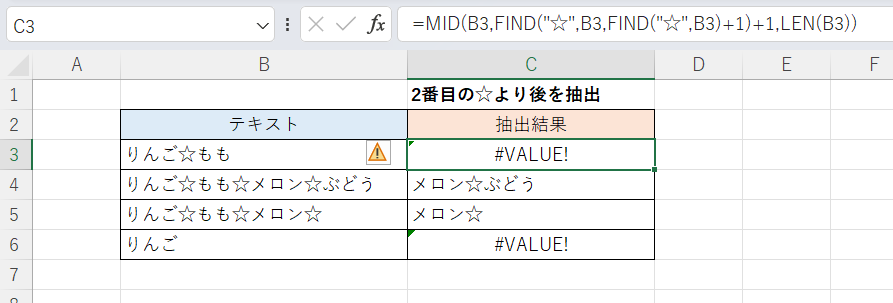
C3セル(下方にフィルコピー)
=MID(B3,FIND("☆",B3,FIND("☆",B3)+1)+1,LEN(B3)) MID関数の第2引数(抽出開始位置)を「FIND("☆",B3,FIND("☆",B3)+1)+1」つまり「2番目『☆』の位置の次」としています。理屈は上記の「n番目のもの以降を抽出する」の例と同様ですのでそちらをご覧ください。
3番目、4番目の指定も可能ではありますが式がどんどん長く複雑になるのが難点です。
続いてTEXTAFTER関数を使う方法です。

C3セル(下方にフィルコピー)
=TEXTAFTER(B3,"☆",2)
同様に3番目以降の指定が可能で、式が長くなる心配もありません。
最後のもの以降を抽出する
まずはMID/FIND関数を使う方法です。
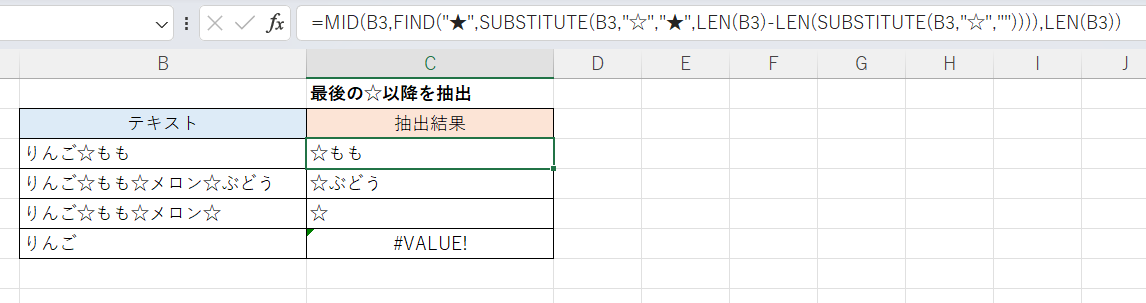
C3セル(下方にフィルコピー)
=MID(B3,FIND("★",SUBSTITUTE(B3,"☆","★",LEN(B3)-LEN(SUBSTITUTE(B3,"☆","")))),LEN(B3)) この「最後のもの」を指定するというのがFIND関数を使う場合の鬼門です。
MID関数の第2引数(抽出開始位置)が非常に長くなっていますが、これは次のようにして「☆」のうち最後のものの位置を求めます。
- 文字列中の「☆」の数(説明上この数をnとする)を求める。
- 文字列中の「☆」のうちn番目(つまり最後のもの)だけを「★」に置き換える。
- FIND関数で「★」の位置を求める。
長い上に置換先の文字である「★」が元の文字列に含まれているとおかしな結果になりますので、この置換先文字は元の文字列に含まれていないものを選ぶ必要があります。
続いてTEXTAFTER関数の例です。
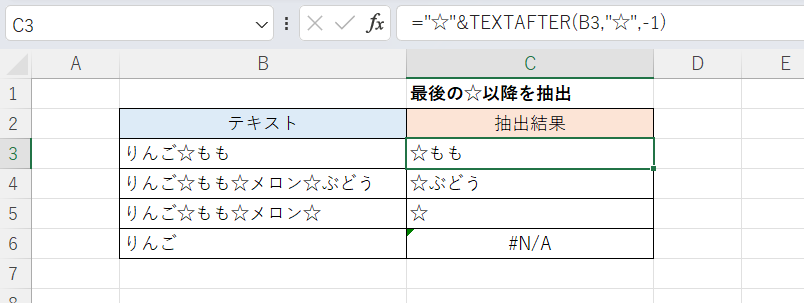
C3セル(下方にフィルコピー)
="☆"&TEXTAFTER(B3,"☆",-1)
このように第3引数を「-1」とするだけで「最後のもの」の位置を指定できます。
なお「-2」とすれば最後から2番目を、「-3」とすれば最後から3番目を指定できます。忘れやすいですが参考まで。
最後のものより後を抽出する
MID/FIND関数を使う方法です。
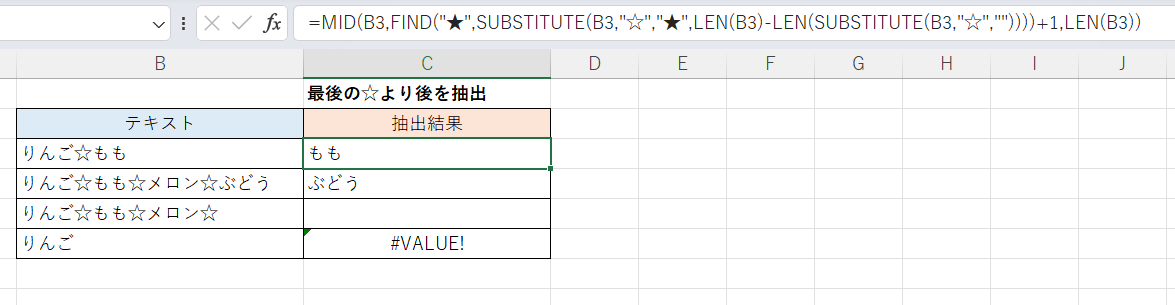
C3セル(下方にフィルコピー)
=MID(B3,FIND("★",SUBSTITUTE(B3,"☆","★",LEN(B3)-LEN(SUBSTITUTE(B3,"☆",""))))+1,LEN(B3)) これも式が長くなります。
詳しくは上記の「最後のもの以降を抽出する」と同様で、第2引数の最後に「+1」が加わっているだけです。
最後にTEXTAFTER関数の例です。
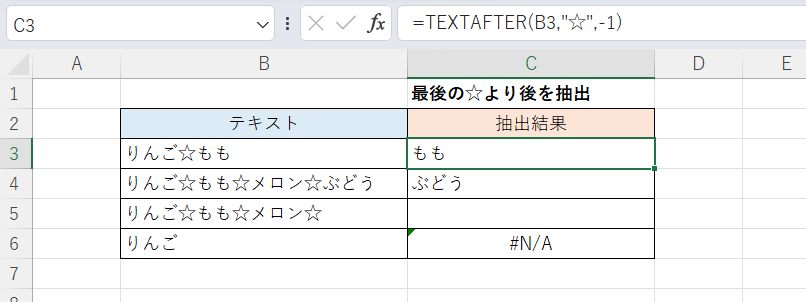
C3セル(下方にフィルコピー)
=TEXTAFTER(B3,"☆",-1)