SUBSTITUTE関数など伝統的な関数を用いる方法だとなかなか複雑になりますが、TEXTAFTER関数が使えれば非常に簡単です。
「右から特定の文字まで」の意味
「右から特定の文字まで抽出する」というのは「特定の文字から右側を抽出する」のと同じことのように思われますが、特定の文字が複数含まれる場合に違ってきます。
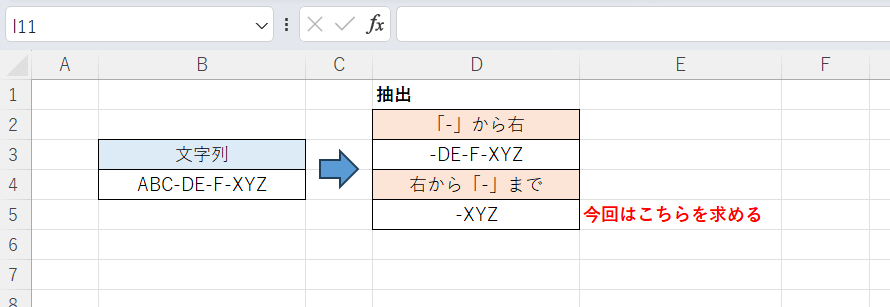
次の画像が具体例となっています。B4セルの文字列「ABC-DE-F-XYZ」のうち「-」から右側を求めると「-DE-F-XYZ」となりますが、右から「-」までを求めると「-XYZ」となります(いずれも「-」を含める場合)。本記事ではこの後者の考え方に沿って、特定の文字を含めずに抽出するケースと含めて抽出するケースをそれぞれ紹介します。
RIGHT/FIND/SUBSTITUTE関数等を使う方法
まずは特定の文字を含めず抽出する例です。
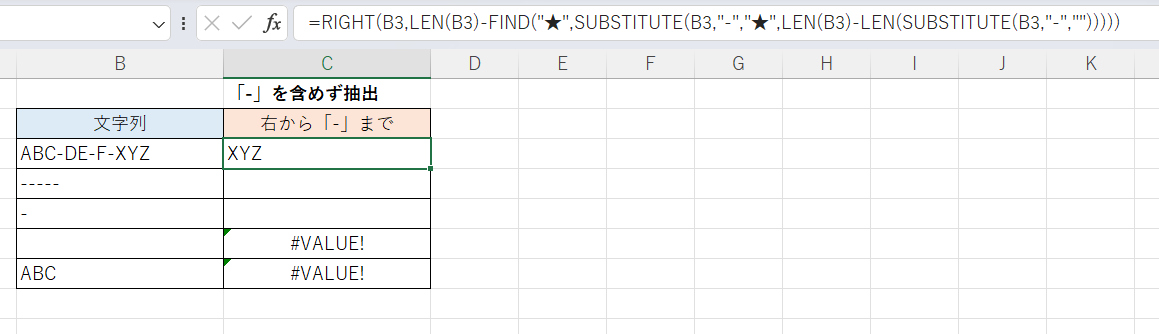
次の画像ではC3セルに式を入力し、B3セルのテキスト中の右から特定の文字「-」までを、ただし「-」を含めず抽出しています。
C4セル以降にも同様の式を入力しており、最後の文字が「-」である場合は空文字列(長さ0の文字列)となり、「-」が含まれない場合はエラーとなります。
C3セル(下方にフィルコピー)
=RIGHT(B3,LEN(B3)-FIND("★",SUBSTITUTE(B3,"-","★",LEN(B3)-LEN(SUBSTITUTE(B3,"-",""))))) かなり面倒な式になります。
概要のみ説明すると、まずSUBSTITITE関数とLEN関数を駆使して「-」のうち最も右にあるものだけを「★」に置き換えています。そしてFIND関数でその「★」の位置(左から数えた位置)を特定し、抽出する長さを計算したうえでRIGHT関数を使い該当する部分を抽出しています。
なお元のテキストに「★」が含まれている場合は置換先として別の文字(テキスト中で使われていない文字)を選択する必要があります(以降でもTEXTAFTER関数を用いる例以外では同様です)。
細部を省略した説明でわかりにくいとは思いますが、「-」の最も右のものを「★」に置き換えてFIND関数でその位置を求めるところについては次の記事で解説していますので参考まで。
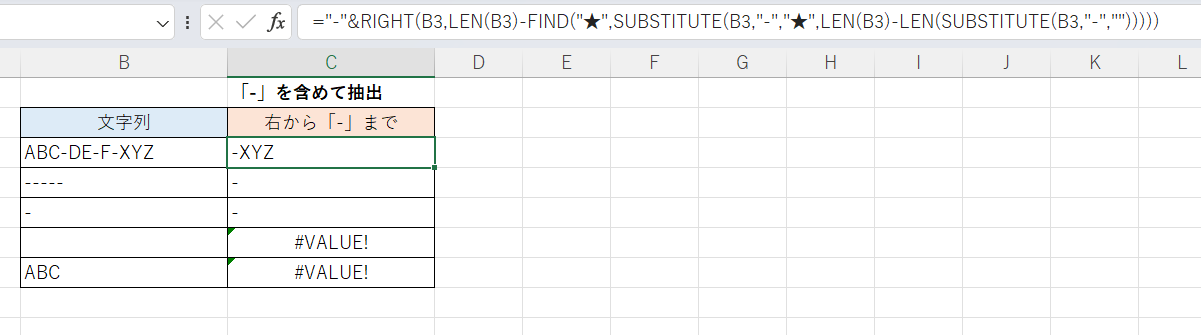
特定の文字「-」を含める場合は先頭に「-」をつなげます。テキストに「-」が含まれない場合でも上記の例と同じ結果になります(「-」だけが返るのではなくエラーになってくれる)。
RIGHT関数の抽出位置を調整する方法も考えられますが、こちらの方が変更が容易かと思います。
C3セル(下方にフィルコピー)
="-"&RIGHT(B3,LEN(B3)-FIND("★",SUBSTITUTE(B3,"-","★",LEN(B3)-LEN(SUBSTITUTE(B3,"-","")))))
REPALCE/FIND/SUBSTITUTE関数等を使う方法
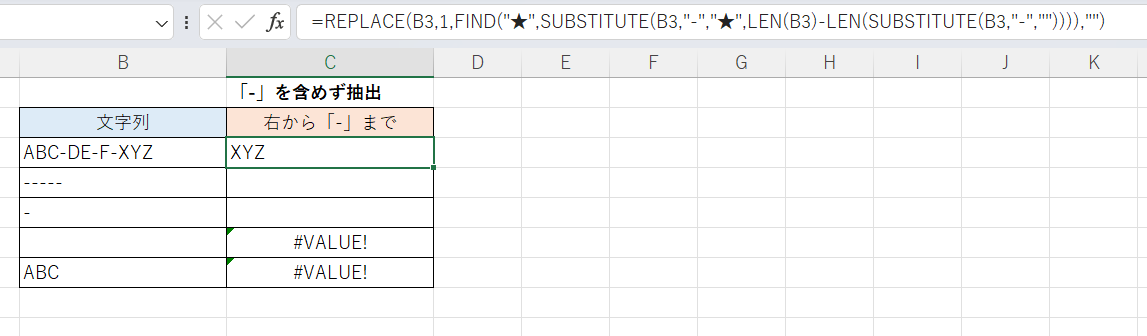
こちらも上記の例とほぼ同様ですが、最終的な抽出段階でRIGHT関数を使うのではなくREPLACE関数を使っています。
C3セル(下方にフィルコピー)
=REPLACE(B3,1,FIND("★",SUBSTITUTE(B3,"-","★",LEN(B3)-LEN(SUBSTITUTE(B3,"-","")))),"") 「-」のうち最も右のものを「★」に置き換えてFIND関数でその位置を特定しているところまでは同じです。
ただし最後にREPLACE関数を使い、1文字目からその位置までを削除する(空文字列に置き換えている)ことで右側を残しているのが違いです。
こちらは特定の文字「-」を含める例です。先頭に「-」をつけただけです。
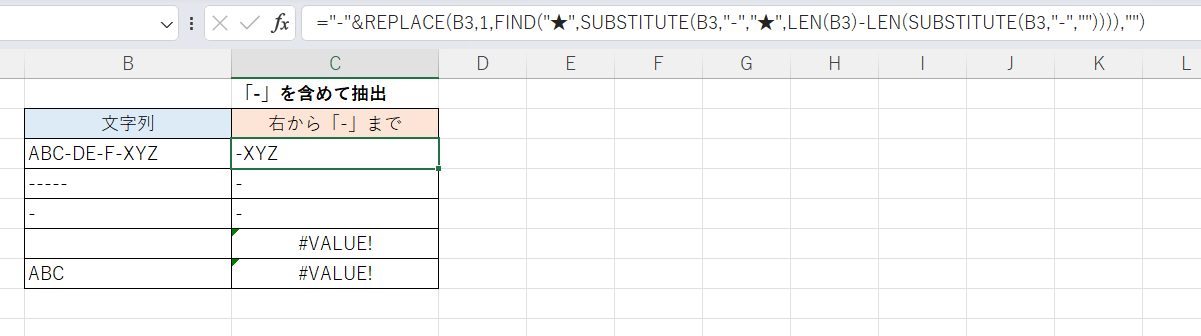
C3セル(下方にフィルコピー)
="-"&REPLACE(B3,1,FIND("★",SUBSTITUTE(B3,"-","★",LEN(B3)-LEN(SUBSTITUTE(B3,"-","")))),"")TEXTAFTER関数を使う方法
比較的新しいTEXTAFTER関数を用いる方法です。
使用できるバージョンは限られますが、上記の例とは比較にならないほど簡単に抽出ができます。
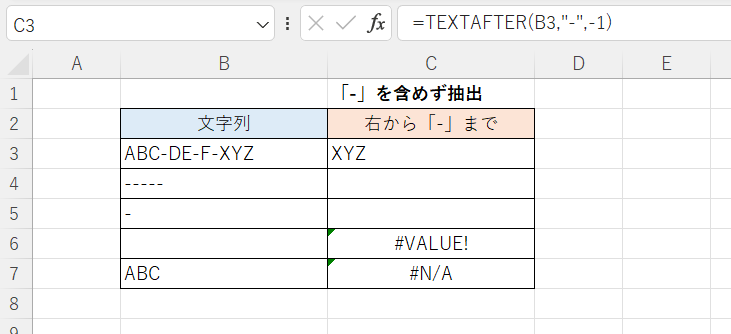
C3セル
=TEXTAFTER(B3,"-",-1)
TEXTAFTER関数はテキスト中の特定の文字より後の部分を抽出する関数ですが、第3引数(抽出位置)を「-1」とすることで特定の文字のうち最後のもの(最も右にあるもの)より後の部分を抽出できます。まさに必要としている抽出内容そのものです。
こちらは「-」を含める例です。これも先頭に「-」をつなげただけです。
最後のセルのエラーの種類が上記例と異なりますが、実用上は特に問題はないでしょう。
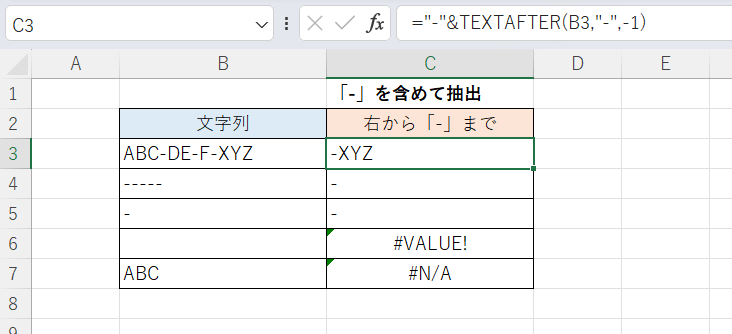
C3セル
="-"&TEXTAFTER(B3,"-",-1)