特にFILTER関数との組み合わせが便利です。
- REGEXMATCH関数により、テキストが正規表現にマッチ(該当)するかどうか判定することができます。
機能と構文
REGEXMATCH関数の機能は「テキストが正規表現の内容にマッチ(該当)するかどうか判定し、TRUEまたはFALSEの値を返す」というものです。
ここで「マッチする」というのは基本的には部分一致判定(テキストが正規表現の内容を含んでいるか)と捉えて間違いありませんが、メタキャラクタ(特別な意味を持つ文字)を使って前方一致や後方一致の判定も可能です。もちろん完全一致判定も可能です。
構文は次の通りです。
=REGEXMATCH(テキスト, 正規表現)
引数は2つあり、ともに必須です。
基本的な使用例
部分一致(~を含む)の判定
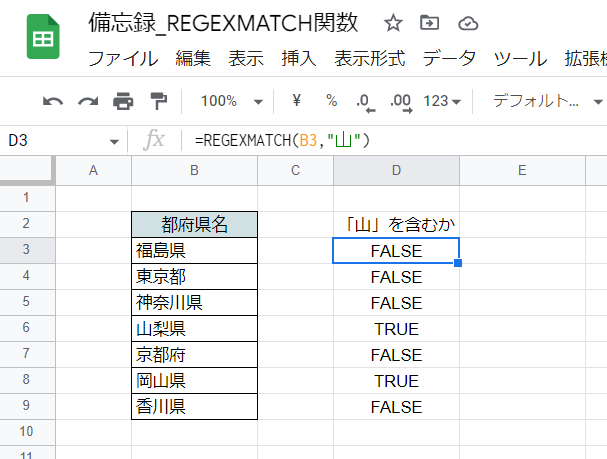
画像ではB列のテキストに対し、「山」の字を含むかどうかの判定を行っています。
式は次のとおりです。
D3セル(下方にコピー)
=REGEXMATCH(B3,"山")
第2引数に「"山"」と指定するだけです。正規表現のメタキャラクタ(特別な意味を持つ記号)は何も使わずに部分一致判定ができます。
前方一致(~で始まる)の判定
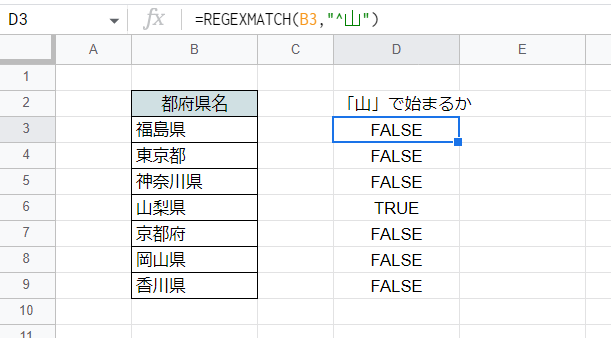
こちらではB列のテキストに対し、「山」の字で始まるかどうかの判定を行っています。
D3セル(下方にコピー)
=REGEXMATCH(B3,"^山")
「^」というメタキャラクタを使用しており、これは正規表現で文字列の先頭を意味します。
よって「^山」というのは「文字列の先頭にある『山』」という意味になりますので、「山」で始まる文字列だけがTRUEと判定されます。
後方一致(~で終わる)の判定
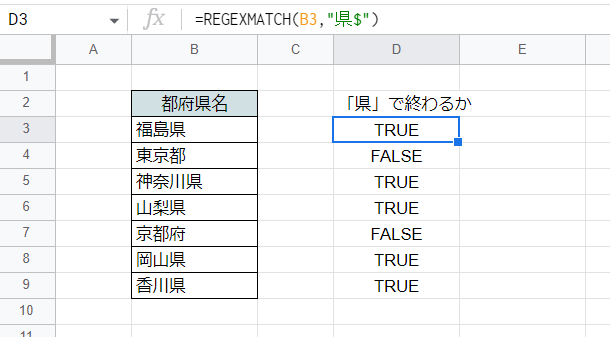
ここではB列のテキストに対し、「県」の字で終わるかどうかの判定を行っています。
D3セル(下方にコピー)
=REGEXMATCH(B3,"県$")
「$」というメタキャラクタを使用しており、これは正規表現で文字列の末尾を意味します。
つまり「県$」というのは「文字列の末尾にある『県』」という意味になりますので、「県」で終わる文字列だけがTRUEと判定されます。
ここで「$県」としてしまうと「文字列の末尾の後にある『県』」という意味になり絶対にマッチしない(TRUEにならない)条件になってしまうので注意が必要です。
数値や日付の扱い
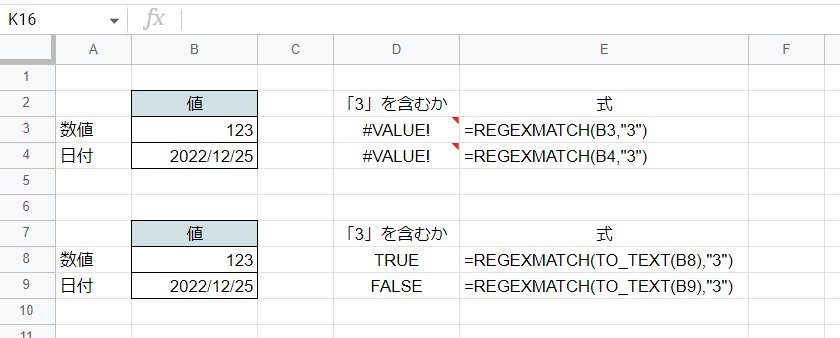
第1引数として数値や日付を入れるとエラーになります(画像のD3,D4セルの例)。
そこで値を文字列に変換しておく必要があり、D8,D9セルではTO_TEXT関数を使って文字列に変換し判定しています。
COUNTIF関数+ワイルドカードとの比較
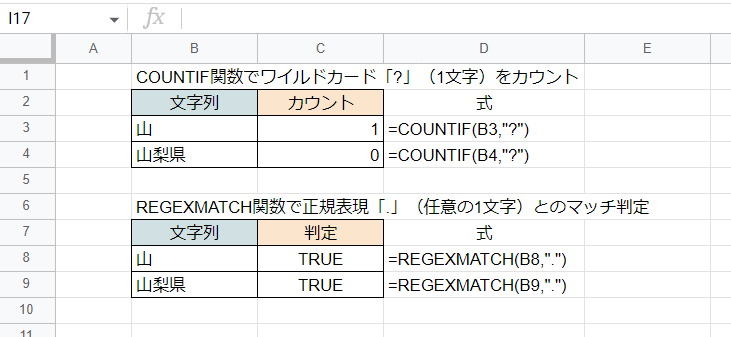
ちょっとした補足ですが、ワイルドカードを使って部分/前方/後方一致の判定ができる関数としてCOUNTIF関数があります。
ただしCOUNTIF関数は完全一致判定を基本にしているので、第2引数の内容が第1引数の全体にマッチしている必要があります。
よって画像のようにワイルドカード「?」にマッチするか判定した場合、1文字の文字列にはマッチ(カウント)しますが3文字の文字列にはマッチしません。
一方でREGEXMATCHは部分一致判定を基本にしているので、メタキャラクタ「.」(ワイルドカードの「?」と同様に任意の1文字を意味します)にマッチするか判定した場合、1文字の文字列にも3文字の文字列にもマッチします(3文字の中の1文字がマッチするからです)。特にメタキャラクタを使っているときに完全一致判定をしているものと勘違いしやすいため注意が必要です。
第2引数を空文字列にした場合
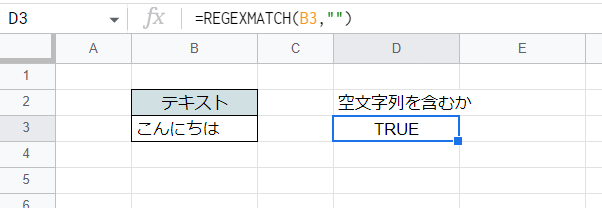
さほど重要でもありませんが、第2引数に空文字列("")を指定すると、上記のようなエラーになるケースでない限り結果はTRUEになります。
これは文字列の先頭・文字の間・末尾にそれぞれ空文字列が存在するものと扱われていてそれにマッチするからです。REGEXMATCH関数というより正規表現ならではの現象です。
第2引数に何も指定しない(カンマまで入れる)場合も同様になります。
応用例
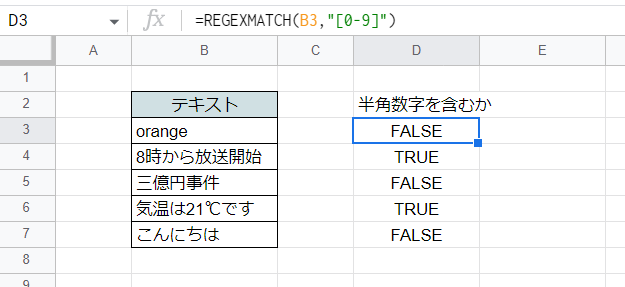
数字を含むか判定する
さまざまな正規表現を覚えれば他の関数では難しい複雑な判定も簡単にできるようになります。
ここでは文字列が半角数字を含むかどうかを判定しています。
D3セル(下方にコピー)
=REGEXMATCH(B3,"[0-9]")
正規表現では0から9までの数字を「[0-9]」と表現できます(ちなみに「\d」としても同じ意味になります)。これにより0から9のいずれかを1文字でも含んでいればTRUEと判定されます。
FILTER関数の条件に使用する
REGEXMATCH関数はFILTER関数との相性がよく、条件として部分一致、前方一致、後方一致を使い分けるのに適しています。
SEARCH関数でもいい線はいきますが大・小文字の区別がつかなくなるのと、特に後方一致判定が面倒になるのでREGEXMATCH関数の方に分があります。
こちらは部分一致判定(~を含む)の例です。
FILTER関数の第2引数にREGEXMATCH関数を使い、都府県のデータのうち名前が「山」で始まるものを抽出しています。
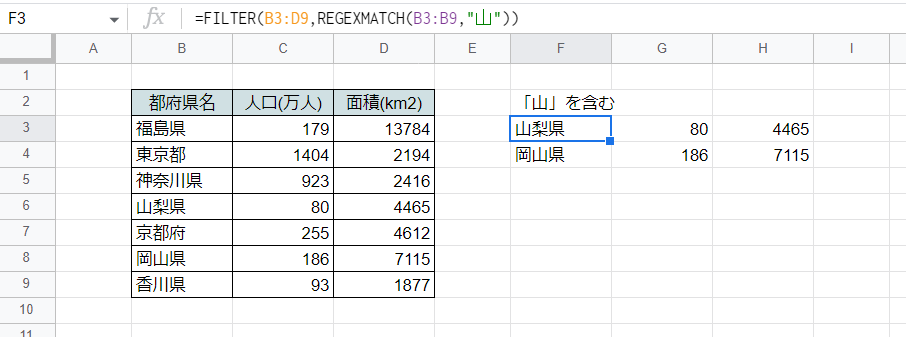
F3セル
=FILTER(B3:D9,REGEXMATCH(B3:B9,"山"))
いちばん最初に紹介した部分一致判定の式をFILTER関数の第2引数に組み込むだけ(ただし範囲はB3:B9に拡張)で抽出ができます。
こちらは前方一致判定(~で始まる)の例です。
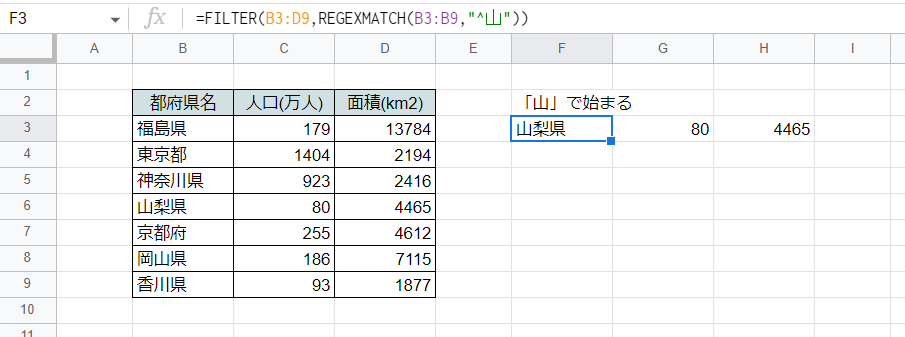
F3セル
=FILTER(B3:D9,REGEXMATCH(B3:B9,"^山"))
最後に後方一致判定(~で終わる)の例です。
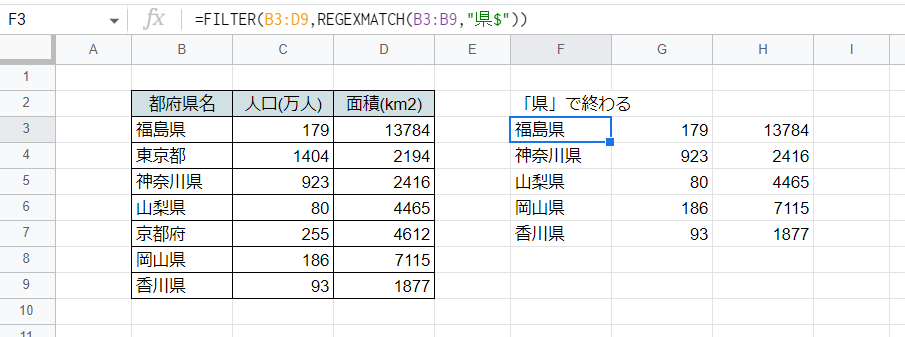
F3セル
=FILTER(B3:D9,REGEXMATCH(B3:B9,"県$"))
正規表現の詳細について
ここで使用した正規表現はごく簡単なものですが、さまざまなメタキャラクタの使い方を覚えればより複雑な内容の判定が可能になります。
次の記事でGoogleスプレッドシートで使える各種の正規表現を紹介しています。