- REGEXEXTRACT関数の第2引数でカッコによるグループ化と波カッコを使った繰り返し回数の指定「{n}」を併用すると、繰り返し中のn番目のものだけを抽出できます。
- (通常期待されるように)1からn番目の繰り返し全体を抽出する場合は非キャプチャグループを用いるのが一つの方法です。
- 量指定子の設定が難解ですが、同一グループ内のn番目のマッチを抽出することも可能となります。
手順
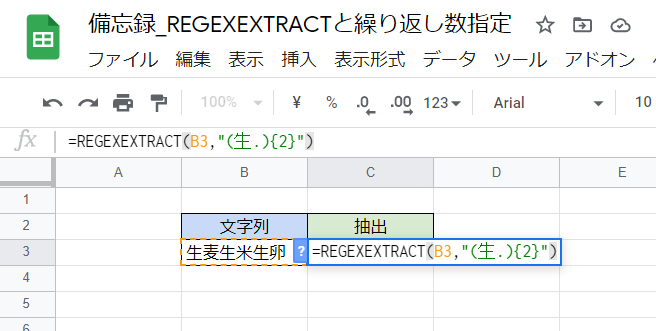
画像ではB3セルに文字列が入力されています。
そこでD3セルに次のような式を入力して一部を抽出しようとしています。
=REGEXEXTRACT(B3,"(生.){2}") REGEXEXTRACT関数を使い、文字列中の「『生』で始まる2文字の2回の繰り返し」を抽出しようという式です。
一見「生麦生米」が抽出されるように見えますが……
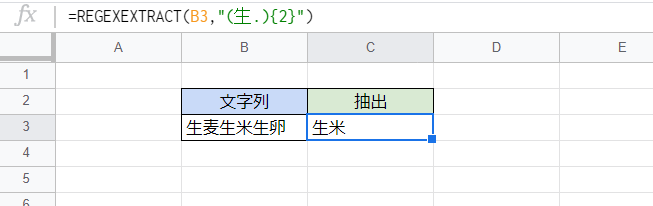
実際に抽出されるのは2番目の「生米」だけです。
波カッコを「{1,2}」としても同様です。
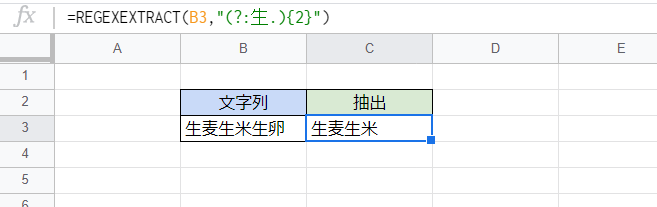
一例として、次の式のように非キャプチャグループ(?:~)を使えば「生麦生米」と抽出することができます。
D3セル
=REGEXEXTRACT(B3,"(?:生.){2}")
さて、最初の式の挙動を見ると、「(生.)」という正規表現にマッチする3個の部分のうち任意のものを簡単に抽出できるように見えます。
さらに言えば、REGEXEXTRACT関数で正規表現にマッチしたn個の部分のうちi番目(任意)のものを抽出する、という厄介な問題が解決しているように見えます。
確かにいい線をいっているのですが少し注意が必要で、文字列が正規表現で表されるパターンの繰り返しになっていないとうまくいきません。
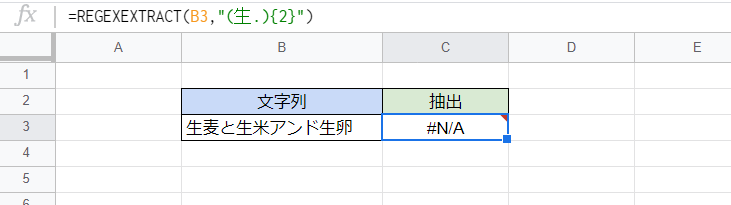
右の画像は2番目の画像からB3セルの文字列を少し変えた結果ですが、「『生』で始まる2文字」が繰り返されておらず3か所に分かれてしまっているので、もはや「生米」という部分をうまく抽出できません。
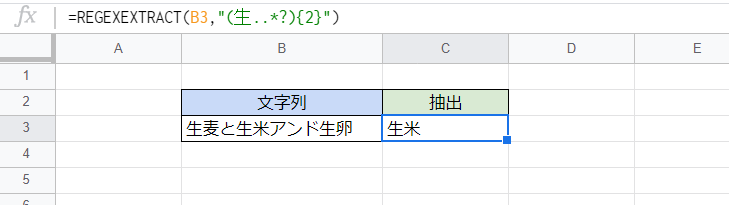
そこで対策として式を少し変えた結果です。
これで2番目の「生米」という部分が抽出できています。
D3セル
=REGEXEXTRACT(B3,"(生..*?){2}") 正規表現のカッコ内に「.*?」が加わっています。
他の言語等と同様の挙動なのか怪しい感じもしますが、これで3か所の「生○」の間に別の文字列が含まれていても形式的には繰り返しているものとみなしてマッチングさせることができ、かつ「生○」のうちi番目のものだけを抽出することができています。
正規表現が本来抽出したい内容より長くなり、しかも個別的な調整が必要になってしまうため応用が難しいのが難点ですが、一応はi番目の抽出が可能となります。